The Age of AI in the Life Sciences: Benefits and Biosecurity Considerations (2025)
Chapter: Appendix A: Mapping the Landscape of AI-Enabled Biological Design
Appendix A
Mapping the Landscape of AI-Enabled Biological Design1
Author: Brian L. Hie
Affiliations: Department of Chemical Engineering, Stanford University, Stanford, CA, USA; Stanford Data Science, Stanford University, Stanford, CA, USA; Arc Institute, Palo Alto, CA, USA
ABSTRACT
This review provides an overview of artificial intelligence–enabled biological models, focusing on their applications in designing biological molecules and systems. We review foundation models that learn data distributions, generative models that sample from these distributions, predictive models that map between biological modalities, and design models that produce desirable biological outputs. The review highlights substantial advances in protein engineering while noting emerging areas in genomic and transcriptomic modeling. We explore these models’ potential to accelerate biological design and reveal new fundamental insights, emphasizing their role in augmenting traditional experimental approaches. We also survey diverse biological datasets underlying these models, emphasizing their crucial role in model development. We also discuss the integration of large language models with biology-specific tools as a promising frontier. Finally, we speculate on future developments, envisioning a synergy between computational simulation and experimental validation in biological discovery and design.
___________________
1 The author is solely responsible for the content of this paper, which does not necessarily represent the views of the National Academies of Sciences, Engineering, and Medicine.
GLOSSARY
Important technical terms, which are italicized throughout the text, are also collected with brief definitions in this glossary, in the order in which they appear in the text:
- Supervised machine learning: A type of machine learning in which models are trained on labeled data to predict specific outputs from given inputs.
- Unsupervised machine learning: A type of machine learning in which models learn patterns and structures from unlabeled data without predefined outputs.
- Scaling hypothesis: An empirical finding that language modeling performance improves predictably as the size of the model, dataset, and computational resources increases.
- Foundation models: Large-scale unsupervised models trained at scale on vast datasets that exhibit broad capabilities across various downstream tasks.
- Multilayer perceptron (MLP): A basic type of neural network with fully connected layers of artificial neurons.
- Convolutional neural networks (CNNs): Neural networks designed to process data dominated by local interactions among features using convolution operations.
- Graph convolutional neural networks (GNNs): Neural networks that operate on graph-structured data, capturing relationships between nodes in the graph.
- Transformer architecture: A neural network architecture that uses self-attention mechanisms to process sequential data, allowing for efficient modeling of long-range dependencies.
- State space models (SSMs): A class of sequence modeling architectures inspired by techniques from signal processing that can be configured to learn local or long-range interactions while maintaining efficient computational scaling.
- Hybrid architectures: Neural network designs that combine different layer types, such as transformer layers or SSM layers, to leverage their respective strengths.
- Autoregressive language modeling: A training objective in which models predict the next token in a sequence given the previous tokens.
- Masked language modeling: A training objective in which models predict masked or corrupted tokens in an input sequence.
- Discrete diffusion modeling: A generative modeling approach that progressively removes and reconstructs artificially corrupted discrete tokens.
- Mean squared error (MSE): A common loss function that measures the average squared difference between predicted and actual values.
- Variational autoencoders (VAEs): Generative models that learn to encode inputs into a latent space and decode them back, often used for generating new data.
- Continuous diffusion modeling: A generative modeling approach that gradually adds and removes noise from continuous data.
- Protein language models: Foundation models trained on large datasets of protein sequences to learn patterns of protein structure and function.
- Single-cell foundation models: Unsupervised models trained on single-cell RNA sequencing data to learn cell-type-specific gene expression patterns.
- Genomic language models: Foundation models trained on DNA sequences to capture patterns of regulatory DNA, RNA, and proteins, as well as their interactions that create systems and organisms.
- One-hot encoding: A simple but effective method of representing categorical data as binary vectors. For a protein sequence, each amino acid is assigned a unique 20-dimensional binary vector in which one element corresponding to that amino acid is 1 and all others are 0.
- Neural sequence embedding: A representation based on using a large pretrained neural network to generate dense vector representations of a sequence, potentially capturing complex patterns within the sequence data learned during pretraining.
INTRODUCTION
From molecular interactions to multicellular organisms, biological complexity has required researchers to develop increasingly sophisticated computational approaches both to understand fundamental biological principles and to engineer new biological systems. Rapid progress in artificial intelligence (AI) also promises to improve our ability to do biological discovery and design and has led to a proliferation of tools with applications that span diverse areas of biological research and engineering. The diversity of these tools, alongside an equally diverse set of applications, creates the need for a comprehensive review that catalogues these innovations and provides a structured framework for understanding their relationships. This paper aims to present a systematic overview of AI-enabled biological models as well as the biological datasets that enable these models. By organizing these tools and tasks coherently, we aim to provide researchers, policymakers, and industry professionals with a clear overview of the current landscape, facilitating more effective
utilization of these technologies and identifying promising areas for future development.
In this review, we begin with an overview and taxonomy of (1) biological foundation models, (2) predictive models, and (3) biological design tools. Our discussion of foundation models will cover biological sequence models within the central dogma, foundation models of biological representations beyond sequences, multimodal models, and generative approaches. We will then explore prediction tools, with special attention to protein structure and function prediction from sequence, as well as multi-omic prediction models. We will then examine biological design tools that generate new sequences with desired properties, which are often aided by property prediction tools. Here, we highlight problems in protein design, structure-based sequence generation, and DNA promoter sequence design. Throughout, we will emphasize the role of generative models and modern deep learning techniques.
We will then consider the datasets used to train these models, assessing their quality and information richness. These include comprehensive sequence databases; structural repositories; large datasets that measure function; and multi-omic datasets spanning genomics, transcriptomics, and proteomics. Finally, we will explore how developments in large language models (LLMs) can be integrated with biology-specific tools. While this integration is still in its early stages, we will speculate on both the potential synergies and challenges in combining general-purpose language models with specialized biological tools, considering applications in scientific literature analysis, experimental design, and biological knowledge integration.
BIOLOGICAL MODELS I: FOUNDATION MODELS
In this review, we define foundation models (Bommasani et al., 2021) using two criteria: (1) the model is trained with an unsupervised objective that attempts to reconstruct the underlying data distribution; and (2) when trained on a sufficiently large and complex dataset, the model demonstrates generalist capabilities across a broad set of downstream tasks, with performance improving as both model and data scale increase (see Figure A-1).
Unlike traditional supervised machine learning, which maps inputs to different types of outputs (e.g., predicting a caption text given an image), unsupervised machine learning models aim to reconstruct their input as accurately as possible (Hastie et al., 2009). This approach encourages the model to learn fundamental patterns and structures within vast amounts of unlabeled data. When trained on sufficiently large and complex datasets (e.g., internet-scale text or images), modern deep learning architectures (Goodfellow, Bengio, and Courville, 2016; Vaswani et al., 2017) have shown the ability to acquire generalist capabilities applicable to a wide
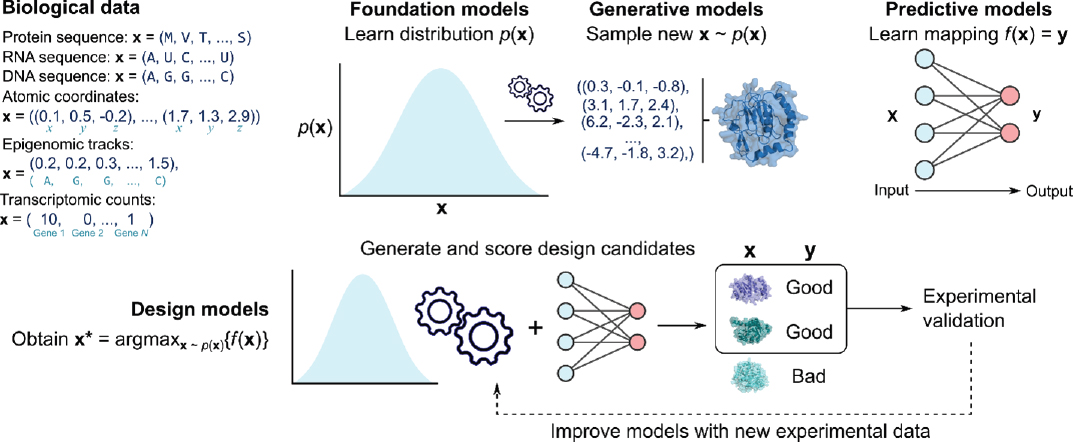
NOTES: Data types include discrete sequences (protein, RNA, and DNA), continuous atomic coordinates (molecules represented as a set of three-dimensional atomic coordinates), continuous epigenomic tracks (epigenomic markers at each genomic position), and discrete transcriptomic count vectors (dimensions corresponding to different genes). Foundation models learn complex data distributions at scale (image illustrates a one-dimensional probability density, but biological distributions are much higher-dimensional), while generative models enable efficient sampling from these distributions (image illustrates a generated set of atomic coordinates that forms a protein structure). Predictive models map between different biological data types, potentially with complex structured outputs. Finally, design models often leverage both generative and predictive models to generate and score design candidates for experimental validation, with new experimental data potentially being used to subsequently improve the models. The image illustrates three protein designs produced by a generative model, two of which are labeled as “good” by a predictive model, which are then selected for experimental validation.
range of downstream tasks, which often differ substantially from the original training objective (Brown et al., 2020). As these models increase in size, they demonstrate improved performance on both the unsupervised reconstruction task and specific downstream tasks. This relationship between model scale and performance is often referred to as the scaling hypothesis or scaling laws (Kaplan et al., 2020; Hoffmann et al., 2022).
Unsupervised models that exhibit these scaling properties are often referred to as foundation models (Bommasani et al., 2021). The ability to learn generalist information across various tasks from a single large-scale unsupervised model distinguishes foundation models from smaller task-specific unsupervised models. The term “foundation” refers to how the information learned through a single unsupervised training objective can transfer to many task-specific downstream applications. Foundation models for text, code, images, and speech have made significant progress in their respective domains. In this review, we examine the current landscape of foundation models for biological data, discussing their progress and potential opportunities.
Preliminaries: Model Architectures and Objectives
Foundation models in biology use neural networks based on a common set of architectures and training objectives. Architectures define how neural connections are arranged within the model, while training objectives are loss functions that guide the optimization of the model. Understanding the distinction between a model’s architecture (e.g., a transformer) and its training objective (e.g., a diffusion model) is crucial for understanding the model’s capabilities and limitations.
Architectures
Several key architectures are fundamental to modern deep learning models and to foundation models in particular. The most standard deep learning architecture is the fully connected neural network, sometimes referred to as a deep neural network or as a multilayer perceptron (MLP) (Rumelhart, Hinton, and Williams, 1986; Goodfellow, Bengio, and Courville, 2016), which consists of an input layer of artificial neurons that receives data, one or more fully connected hidden layers to process the data, and an output layer to generate the final predictions. Convolutional neural networks (CNNs) (LeCun et al., 1989; Goodfellow, Bengio, and Courville, 2016) process information organized by position (e.g., one-dimensional text or two-dimensional images), focusing on interactions between nearby elements. Graph convolutional neural networks (GNNs) (Scarselli et al., 2009; Wu et al., 2019), a subvariant of CNNs, model elements as nodes
and consider interactions only between connected nodes, making them useful for graph-representable data. These architectures excel when the data distribution is dominated by local interactions. The transformer architecture (Vaswani et al., 2017), based on an operation called self-attention (Bahdanau, Cho, and Bengio, 2014), allows each element in an input sequence to interact with all others, regardless of distance. This enables the capture of both local and long-range dependencies, proving remarkably effective for many tasks. However, its all-by-all element comparison leads to quadratic computational scaling with sequence length. State space models (SSMs) (Gu and Dao, 2023; Poli et al., 2023) are an emerging class of architectures that can be configured to prefer learning local or long-range interactions while maintaining near-linear computational scaling with sequence length. Hybrid architectures combine different layer types (e.g., a mixture of CNN layers, transformer layers, or SSM layers) within a single deep neural network, potentially benefiting from the strengths of each constituent architecture (Poli et al., 2024).
Objectives
A foundation model can be trained with different objectives that all attempt, in some way, to reconstruct the input. Different objectives are used depending on whether the underlying data are discrete or continuous. When data samples are sequences of discrete tokens (e.g., a sequence of DNA base pairs), a typical language model is trained via autoregressive language modeling in which the model is asked to predict the next token given a sequence prefix, enforcing a left-to-right order (Radford et al., 2019). An alternative training objective for discrete sequence models is masked language modeling in which a model is asked to predict the true values of positions that are masked or corrupted in the input (Devlin et al., 2018). A generalization of masked language modeling is discrete diffusion modeling in which a model is trained to progressively remove artificially masked or corrupted tokens in its input (Lou, Meng, and Ermon, 2023). When the input takes the form of continuous data (e.g., an image containing pixels along a color spectrum), a common objective is to simply minimize the mean squared error (MSE) separating the prediction value from the ground truth value (Hastie et al., 2009). For example, MSE loss is frequently used in a class of models called variational autoencoders (VAEs) (Kingma and Welling, 2014), which encode the input as a Gaussian latent variable encouraging a smooth representation of the data, combined with an MSE loss that compares the output of a decoder with the original sample. While VAEs can successfully represent some simple data distributions, more powerful recent models have been trained with continuous diffusion modeling (Ho, Jain, and Abbeel, 2020) in which, as in the discrete
case, the model is trained to iteratively remove artificial noise from an input sample. Importantly, any architecture can be trained with any objective, though certain architectures are commonly paired with certain objectives (e.g., autoregressive transformer models).
Generative Models
Some objectives are particularly suited for efficient sampling from learned probability distributions. Autoregressive models, for example, enable left-to-right sampling based on the model’s next-token predictions. A VAE enables decoding of Gaussian noise into new samples. Both continuous and discrete diffusion models facilitate iterative denoising or reconstruction of purely noised or corrupted samples. Models trained with these sampling-friendly objectives are often referred to as generative models.
Modeling the Distribution of Sequences
We first consider a major class of biological foundation models in which the underlying data are a sequence of discrete tokens, where each token corresponds to a DNA base pair, an RNA base pair, or a protein amino acid. We describe notable models, along with their corresponding model architecture and objective, in the sections below and in Table A-1.
TABLE A-1 Foundation Models of Biological Data
| Category | Model name | Architecture | Training objective | Reference |
|---|---|---|---|---|
| General protein sequence | ESM-1b | Transformer | Masked language modeling | Rives et al., 2021 |
| General protein sequence | ESM-1v | Transformer | Masked language modeling | Meier et al., 2021 |
| General protein sequence | ESM-2 | Transformer | Masked language modeling | Lin et al., 2023 |
| General protein sequence | ESM3 | Transformer | Discrete diffusion modeling | Hayes et al., 2024 |
| General protein sequence | ProGen | Transformer | Autoregressive language modeling | Madani et al., 2021 |
| General protein sequence | ProGen2 | Transformer | Autoregressive language modeling | Nijkamp et al., 2023 |
| General protein sequence | CARP | CNN | Masked language modeling | Yang, Fusi, and Lu, 2024 |
| Category | Model name | Architecture | Training objective | Reference |
|---|---|---|---|---|
| General protein sequence | ProteinBERT | Transformer | Masked language modeling | Brandes et al., 2023 |
| General protein sequence | TAPE | Transformer | Masked language modeling | Rao et al., 2019 |
| General protein sequence | ProtTrans | Transformer | Autoregressive language modeling | Elnaggar et al., 2022 |
| General protein sequence | ProtGPT2 | Transformer | Autoregressive language modeling | Ferruz, Schmidt, and Höcker, 2022 |
| General protein sequence | RITA | Transformer | Autoregressive language modeling | Hesslow et al., 2022 |
| Antibody protein sequence | AbLang | Transformer | Masked language modeling | Olsen, Moal, and Deane, 2022 |
| Antibody protein sequence | IgBERT | Transformer | Masked language modeling | Kenlay et al., 2024 |
| Antibody protein sequence | IgT5 | Transformer | Autoregressive language modeling | Kenlay et al., 2024 |
| Antibody protein sequence | AntiBERTa | Transformer | Autoregressive language modeling | Leem et al., 2022 |
| Antibody protein sequence | AntiBERTy | Transformer | Autoregressive language modeling | Ruffolo, Gray, and Sulam, 2021 |
| Antibody protein sequence | Sapiens | Transformer | Masked language modeling | Prihoda et al., 2022 |
| Coding RNA sequence | CaLM | Transformer | Masked language modeling | Outeiral and Deane, 2024 |
| Coding RNA sequence | CodonBERT | Transformer | Masked language modeling | Ren et al., 2024 |
| Noncoding RNA sequence | RiNALMo | Transformer | Masked language modeling | Penić et al., 2024 |
| Noncoding RNA sequence | RNA-FM | Transformer | Masked language modeling | Chen et al., 2022 |
| Noncoding RNA sequence | Uni-RNA | Transformer | Masked language modeling | Wang et al., 2023 |
| Noncoding RNA sequence | RNAErnie | Transformer | Masked language modeling | Wang et al., 2024 |
| Genomic DNA sequence | GenSLM | Transformer | Autoregressive language modeling | Zvyagin et al., 2023 |
| Category | Model name | Architecture | Training objective | Reference |
|---|---|---|---|---|
| Genomic DNA sequence | Nucleotide Transformer | Transformer | Masked language modeling | Dalla-Torre et al., 2023 |
| Genomic DNA sequence | GPN | CNN | Masked language modeling | Benegas, Batra, and Song, 2023 |
| Genomic DNA sequence | regLM | Transformer | Autoregressive language modeling | Lal et al., 2024 |
| Genomic DNA sequence | HyenaDNA | SSM | Autoregressive language modeling | Nguyen, Poli, Faizi, et al., 2024 |
| Genomic DNA sequence | Caduceus | SSM | Autoregressive language modeling | Schiff et al., 2024 |
| Genomic DNA sequence | Evo | Hybrid (SSM + Transformer) | Autoregressive language modeling | Nguyen, Poli, Durrant, et al., 2024 |
| Molecular structure | RFdiffusion | Hybrid (GNN + Transformer) | Continuous diffusion | Watson et al., 2023 |
| Molecular structure | Chroma | GNN | Continuous diffusion | Ingraham et al., 2023 |
| Molecular structure | Protpardelle | Transformer | Continuous diffusion | Chu et al., 2024 |
| Cellular transcriptomes | Geneformer | Transformer | Masked language modeling | Theodoris et al., 2023 |
| Cellular transcriptomes | scBERT | Transformer | Masked language modeling | Yang et al., 2022 |
| Cellular transcriptomes | scFoundation | Transformer | Masked language modeling | Hao et al., 2024 |
| Cellular transcriptomes | scGPT | Transformer | Specialized autoregressive language modeling | Cui et al., 2024 |
NOTE: Summary of various foundation models across different categories of biological data, including protein sequences, antibody sequences, RNA sequences, genomic DNA sequences, molecular structures, and cellular transcriptomes. For each model, the architecture, training objective, and citation are also provided.
General Protein Sequence
Many biological sequence models have been trained on large corpora of protein amino acid sequences across diverse protein families and have been shown to learn properties of both structure and function (Bepler and Berger, 2021). By learning which positions in a sequence input are useful when predicting values at other positions, protein language models identify covarying positions across protein evolution, which typically reflects structural proximity. By learning which amino acids are more likely (or unlikely) at given positions, they also learn which mutations are better (or worse) tolerated. A notable suite of protein language models is the ESM family of models, including the first-generation ESM-1b model (released as a general-purpose foundation model) (Rives et al., 2021) and ESM-1v models (specialized to the task of variant effect prediction) (Meier et al., 2021) and the second-generation ESM-2 models (released at different scales from 6 million to 15 billion parameters) (Lin et al., 2023); we discuss ESM3, the third-generation ESM model (Hayes et al., 2024), under the subsection on multimodal models below. ESM-1 and ESM-2 models are trained with masked language modeling and use a standard transformer architecture. Another notable class of models is the ProGen family of models, including the first ProGen model (Madani et al., 2021) and ProGen2 (released at different scales from 151 million to 6 billion parameters) (Nijkamp et al., 2023). ProGen models are also transformers trained on diverse protein families using an autoregressive language modeling objective and have been used to sample diverse sequences from enzyme families while retaining catalytic activity (Madani et al., 2023). Several other notable masked language models, which are evaluated and used as general-purpose protein language models, include CARP (Yang, Fusi, and Lu, 2024), ProteinBERT (Brandes et al., 2023), and TAPE (Rao et al., 2019). Other notable autoregressive language models include ProtTrans (Elnaggar et al., 2022), ProtGPT (Ferruz, Schmidt, and Höcker, 2022), and RITA (Hesslow et al., 2022).
Antibody Protein Sequence
Several protein language models have been developed specifically for antibody sequences. These include AbLang (Olsen, Moal, and Deane, 2022), IgBert and IgT5 (Kenlay et al., 2024), AntiBERTa (Leem et al., 2022), AntiBERTy (Leem et al., 2022), and Sapiens (Prihoda et al., 2022). The ProGen2 suite also contains a version that is fine-tuned on antibody sequences. These models typically train on sequence datasets of the heavy chain variable region (VH) and light chain variable region (VL), which form the antigen-binding part of antibodies and are highly diverse. The largest antibody sequence database is the Observed Antibody Space (OAS),
containing ~2.4 billion VH and VL sequences from animal immune cells. Interestingly, specializing models on antibody datasets like OAS often results in degraded performance on tasks like mutational effect prediction compared to general protein language models, suggesting that some antibody-specific models may lose general structural and functional information learned by training on many protein families (Nijkamp et al., 2023; Hie et al., 2024).
Coding RNA Sequence
Each protein amino acid is encoded by an RNA codon with three base pairs, where 64 codons encode the 20 canonical amino acids plus three stop codons. Rather than train on sequences with an amino acid vocabulary, some models train on sequences with a codon vocabulary. Codon models can capture structural and functional information similar to protein language models while also incorporating codon biases that contain species-related information. In turn, these codon biases can have functional effects on biological processes like translation rate or fidelity. Codon language models include CaLM (Outeiral and Deane, 2024) and CodonBERT (Ren et al., 2024), which can be competitive with or even outperform protein language models on function prediction tasks and transcript abundance datasets.
Noncoding RNA Sequence
Sequence models are also trained on large databases of noncoding RNA (ncRNA) sequences, such as sequences of transfer RNAs (tRNAs), ribosomal RNAs (rRNAs), or regulatory ncRNAs. Many ncRNAs rely on functionally relevant secondary or tertiary structure formation, and mutations can substantially affect their functional activity. Inspired by the success of protein language models at learning analogous aspects of structure and function, ncRNA language models are evaluated on similar tasks. Notable ncRNA models include RiNALMo (Penić et al., 2024), RNA-FM (Chen et al., 2022), Uni-RNA (Wang et al., 2023), and RNAErnie (Wang et al., 2024). These models are smaller than typical protein language models (the largest is RiNALMo at 650 million parameters) and have made some early-stage progress on structure and function prediction tasks.
Genomic DNA Sequence
DNA sequence, the fundamental layer of information in molecular biology, encodes proteins, RNA, and regulatory elements. The vast scale of genomic data presents substantial challenges for sequence modeling, leading
to the development of various genomic sequence models with different architectures. These range from models that combine nucleotides into larger tokens, such as GenSLM (Zvyagin et al., 2023) or Nucleotide Transformer (Dalla-Torre et al., 2023), to those maintaining single nucleotide resolution that operate at shorter sequence lengths, such as GPN (Benegas, Batra, and Song, 2023) or regLM (Lal et al., 2024), with recent architectures like Hyena or Mamba offering longer context windows (Nguyen, Poli, Faizi, et al., 2023; Schiff et al., 2024). Genomic sequence models have diverse applications, including fitness prediction of genetic variants using models like GPN-MSA (Benegas et al., 2024) (similar to how protein sequence models are used for fitness prediction). Another major application is generative, with models like regLM or DNA-Diffusion (DaSilva et al., 2024) emphasizing novel sequence design via autoregressive sampling or discrete diffusion. Models like GenSLM and Nucleotide Transformer emphasize transfer learning for tasks such as gene annotation and chromatin accessibility prediction using the embeddings learned by the DNA language model. More capable language models, trained with billions of parameters on hundreds of billions of base pairs with long context, such as Evo (Nguyen, Poli, Durrant, et al., 2024), have the capacity to make progress on both predictive and generative tasks and at multiple levels of biological complexity.
Modeling the Distribution of Other Biological Modalities
While sequence models have dominated much of the recent progress in biological foundation models, there are notable efforts to model distributions of other biological data modalities that also leverage modern architectures, training objectives, and scale. These non-sequence modalities provide complementary insights into biological systems beyond the genetic information contained in DNA, RNA, and protein sequences.
Molecular Structure
Recent advancements in generative models have expanded to encompass atomic-level protein structures, most notably in the realm of de novo protein design, in which the goal is to design proteins with structures that are unconstrained by the natural repertoire of protein structures and folds. Fundamentally, these molecules are represented as a set of atoms, where an atom is defined by its (x, y, z) coordinates. Early generative models of protein structure based on VAEs were proposed to generate the backbone atomic coordinates of proteins (Lin et al., 2021). Diffusion modeling, which led to more powerful generative models of images, has also shown particular promise in protein structure generation. An early protein diffusion model demonstrating the feasibility of this approach was proposed
by Anand and Achim (2022); more advanced protein backbone diffusion models, such as RFdiffusion (Watson et al., 2023) and Chroma (Ingraham et al., 2023), apply progressive noise to known protein backbone coordinates during training and learn to reverse this process, generating diverse and realistic protein backbones. Recent models such as Protpardelle (Chu et al., 2024) have extended this approach to generating all of the atoms in a protein structure (both the backbone atoms and side-chain atoms). These generative models are either applied unconditionally (simply generating a complete structure from scratch) or conditionally (fixing a part of the structure and generating a compatible completion of the structure). Conditional generation is particularly useful for generating a protein that binds to another target protein (Bennett et al., 2024), where the user conditions on the target and the binder are generated by, for example, a diffusion model. Beyond proteins, conditional diffusion models have also been used to design small molecules or peptides that bind to a given protein, which has applications in small molecule drug design (Peng et al., 2022; Huang et al., 2024).
Cellular Transcriptomes
Ideas from sequence modeling have influenced models of transcriptomic data collected by single-cell RNA sequencing (scRNA-seq) technologies. In this formulation, each sample represents a single cell described by a vector of integer RNA molecule counts, corresponding to expression levels of different genes. Single-cell foundation models adapt concepts from autoregressive and masked language modeling, applying analogous objectives to these gene expression vectors. Several of these single-cell foundation models have been proposed, including Geneformer (Theodoris et al., 2023), scBERT (Yang et al., 2022), scFoundation (Hao et al., 2024), and scGPT (Cui et al., 2024), which all learn patterns in scRNA-seq data by predicting gene expression levels of some genes based on the gene expression levels of other genes. Consequently, these models can generate realistic expression profiles, impute missing data, and provide insights into cell types and states. While these models could theoretically also learn complex genetic interactions and regulatory networks, the extent to which these higher-order concepts are learned directly by the current models during pretraining appears to be more limited (Kedzierska et al., 2023). An important challenge in this domain is the lack of pretraining data available compared to protein or genomic language models. While there are 50–100 million publicly available single-cell transcriptomes, these represent around several thousand underlying cell types; and while a transcriptome is theoretically high-dimensional (~20,000 genes in the human transcriptome), many of these dimensions are highly correlated and can be well represented by tens of principal components. Progress in
single-cell transcriptomic modeling is most likely data limited compared to other domains.
Multimodal Foundation Models
While we have primarily discussed single-modality foundation models, a growing trend is the development of multimodal foundation models in biology. These models are trained with unsupervised objectives to learn information about multiple biological modalities simultaneously. Some models, like the genomic sequence model Evo (Nguyen, Poli, Durrant, et al., 2024), use a single fundamental data type (DNA) to capture information across multiple modalities (RNA and protein), enabling multimodal generative tasks across the central dogma. Others, such as ESM3 (Hayes et al., 2024), explicitly combine data from disparate modalities, taking protein sequence, structure, and function as input and training with a masked reconstruction objective across all three.
The motivation for multimodal learning extends beyond capturing different facets of biological processes. Integrating multiple data modalities allows for the incorporation of additional constraints in the learning process, potentially reducing the number of learned parameters and leading to more compact yet equally capable models. This approach holds promise for democratizing access to powerful models, making them more accessible to academic laboratories and individual researchers.
Furthermore, multimodal models offer an opportunity to incorporate biological priors that encode physics and expert knowledge. This is crucial because data alone may never be sufficient to fully capture complex biological processes occurring at various timescales. By integrating these priors, models could learn more robust and biologically relevant representations. For instance, recent work has demonstrated that while language models trained solely on sequence data can capture some structural information, they still struggle at remote homology prediction, highlighting that sequence-only approaches could benefit from additional data modalities (Kabir et al., 2024).
However, significant challenges remain in multimodal biological modeling. Current models often do not fully account for the disparate processes, timescales, granularities, and varying fidelities of different biological data types. Resolving these discrepancies and effectively integrating diverse data sources remains an open area of research.
Despite these challenges, the development of multimodal foundation models represents a promising direction for complex biological modeling. The ability of these models to learn joint data distributions, incorporate diverse constraints, and potentially yield more efficient models aligns well with biology’s inherently multimodal and multiscale nature. As the field
progresses, we anticipate further advancements in integrating multiple data modalities and biological priors, leading to more comprehensive and robust models of biological systems.
BIOLOGICAL MODELS II: PREDICTIVE MODELS
Predictive models in computational biology serve a crucial role by mapping one biological modality to another (see Figure A-1), often aimed at simulating complex biological processes or experimental outcomes. Unlike foundation models, which are unsupervised and learn general patterns, prediction models are typically supervised and designed for specific tasks. These models aim to transform input data, such as biological sequences, into output predictions of properties, structures, or functions that are often experimentally challenging or resource-intensive to determine. This approach has led to advances in various areas of biology, from protein structure prediction to functional annotation and epigenomic profiling.
There are many supervised or predictive modeling efforts in biology, often using lightweight models either with simple input features or input features derived from a foundation model. In this review, rather than attempting to document all examples of supervised learning in biology, we instead focus on challenging prediction tasks that are widely used as part of biological design workflows. These prediction tasks are largely focused on biomolecular applications given the large amount of research focused on protein design, though we also review prediction of epigenomic features that is used in DNA regulatory design as well. We also focus mostly on prediction tasks involving complex structured outputs that often require specialized neural network architectures and information-rich training datasets. We also provide a summary of these predictive models in Table A-2.
| Category | Model name | Input data type | Output data type | Citation(s) |
|---|---|---|---|---|
| Sequence to structure | AlphaFold | Protein sequence | 3D protein structure | Senior et al., 2020 |
| Sequence to structure | AlphaFold2 | Protein sequence | 3D protein structure | Jumper et al., 2021 |
| Sequence to structure | AlphaFold3 | Biomolecular sequence | 3D biomolecular structure | Abramson et al., 2024 |
| Sequence to structure | ESMFold | Protein sequence | 3D protein structure | Lin et al., 2023 |
| Category | Model name | Input data type | Output data type | Citation(s) |
|---|---|---|---|---|
| Sequence to structure | OmegaFold | Protein sequence | 3D protein structure | Wu et al., 2022 |
| Sequence to structure | RoseTTAFold All-Atom | Biomolecular sequence | 3D biomolecular structure | Krishna et al., 2024 |
| Image to structure | CryoDRGN | Cryo-EM images | 3D protein volume | Zhong et al., 2021 |
| Image to structure | cryoSPARC | Cryo-EM images | 3D protein volume | Punjani et al., 2017 |
| Image to structure | tomoDRGN | Cryo-ET images | 3D protein volume | Powell and Davis, 2024 |
| Image to structure | CryoDRGN-ET | Cryo-ET images | 3D protein volume | Rangan et al., 2024 |
| Protein fitness | Low-N supervision | Protein sequence | Fitness score | Biswas et al., 2021; Hsu, Nisonoff, et al., 2022 |
| Protein fitness | General language models | Protein sequence | Fitness score | Livesey and Marsh, 2020, 2023; Meier et al., 2021 |
| Viral protein fitness | Constrained Semantic Change Search (CSCS) | Viral protein sequence | Escape score | Hie et al., 2021 |
| Viral protein fitness | EVEscape | Viral protein sequence | Escape score | Thadani et al., 2023 |
| Viral protein fitness | Early-Warning System | Viral protein sequence | Escape score | Beguir et al., 2023 |
| Viral protein fitness | CoVFit | Viral protein sequence | Epidemiological fitness | Ito et al., 2024 |
| Multi-omic prediction | Enformer | DNA sequence | Epigenomic tracks | Avsec et al., 2021 |
| Multi-omic prediction | Borzoi | DNA sequence | Gene expression tracks | Linder et al., 2023 |
NOTE: This table summarizes various predictive models across different categories, including sequence-to-structure prediction, image-to-structure reconstruction, protein fitness prediction, viral fitness prediction, and multi-omic prediction. For each model, the input and output data types are provided, illustrating the diverse range of prediction tasks using modern machine learning methods.
Notable Prediction Task 1: Molecular Structure Prediction
Sequence to Structure
Protein structure prediction, exemplified by AlphaFold, represents a notable breakthrough in computational biology. This task involves determining a protein’s three-dimensional (3D) structure from its amino acid sequence. Notable modeling efforts that advanced this field incorporated physical information, coevolutionary statistical data, and deep learning architectures. Building on these ideas and the preliminary success of an initial AlphaFold model (Senior et al., 2020), AlphaFold2 achieved prediction performance that approaches or matches experimental accuracy for many important proteins, reducing reliance on time-consuming experimental methods like X-ray crystallography (Jumper et al., 2021). The latest iteration, AlphaFold3, extends molecular structure prediction beyond proteins to include other modalities such as small molecules, nucleic acids, and lipids from their sequence descriptions (Abramson et al., 2024). Complementing these advancements, language models like ESM have also contributed to structure prediction models. Trained on vast protein sequence datasets, these models capture deep evolutionary relationships and form the basis for single-sequence structure prediction tools such as ESMFold (Lin et al., 2023) and OmegaFold (Wu et al., 2022). By leveraging the rich information encoded in protein language models, these tools can predict structures accurately without requiring multiple sequence alignments of evolutionarily related proteins that are critical to AlphaFold’s performance. However, language model–based approaches to protein structure prediction have not yet matched the level of accuracy achieved by AlphaFold2 or AlphaFold3. Aside from AlphaFold3, other notable models attempt to predict multimodal biomolecular structures. RoseTTAFold All-Atom (Krishna et al., 2024) models the structures of proteins alongside nucleic acids, metal ions, small molecules, and post-translational modifications, though with lower accuracy than AlphaFold3. Diffusion modeling approaches have been applied to predicting the structural pose of small molecules that bind to proteins (Corso et al., 2023), which is an important problem in small molecule drug design.
Image to Structure
Complementing sequence-based structure prediction, an important area of research focuses on inferring protein volumes from cryo-electron microscopy (cryo-EM) and cryo-electron tomography (cryo-ET) images (Benjin and Ling, 2020). A protein volume is a 3D representation of the electron density distribution within a protein, depicting the spatial
arrangement of its mass. Notable work in this field includes CryoDRGN (Zhong et al., 2021) and cryoSPARC (Punjani et al., 2017; Punjani and Fleet, 2021), which use deep learning techniques to reconstruct (potentially heterogeneous) 3D protein volumes from cryo-EM data, and tomoDRGN (Powell and Davis, 2024) and CryoDRGN-ET (Rangan et al., 2024) for 3D reconstruction from cryo-ET data. Although these volumes do not directly provide atomic-level details, they serve as crucial intermediates in structure determination; to derive the actual protein structure from a volume, researchers employ computational methods that fit atomic models into the density map, leveraging prior knowledge of the protein’s sequence and secondary structure predictions (Benjin and Ling, 2020). CryoDRGN and similar approaches are particularly valuable for capturing protein dynamics, as they can reveal conformational heterogeneity and structural flexibility. By leveraging advanced machine learning algorithms to generate and interpret these volumes, these methods enhance the determination of structures for challenging protein targets and improve understanding of protein behavior in near-native environments.
Notable Prediction Task 2: Protein Fitness Prediction
Many supervised machine learning models predict protein fitness as a scalar value, trained on existing datasets that map protein sequences to fitness values. These models input protein sequences, represented either through simple one-hot encoding (where each amino acid is assigned a unique binary vector) or more advanced neural sequence embeddings from foundation models. The choice of input representation can substantially impact model performance. Most supervised models use straightforward approaches such as linear regression, Gaussian process regression for predictions with uncertainty estimates, random forest regressors, or small MLPs or CNNs. The choice of features and the regression model often depends on factors like dataset size, fitness landscape complexity, and requirements for interpretability or uncertainty quantification (Biswas et al., 2021; Hsu, Nisonoff, et al., 2022).
Unsupervised models of protein sequences, trained on large datasets of naturally occurring proteins, have demonstrated remarkable success in zero-shot prediction of mutational effects on protein fitness (Livesey and Marsh, 2020, 2023). These models leverage sequence likelihoods to predict the impact of mutations, with lower likelihoods generally indicating more deleterious effects. This computational approach can be thought of as an in silico version of deep mutational scanning (DMS), an experimental technique that measures the functional effects of thousands of small mutations in a protein (e.g., all possible single-amino-acid substitutions) (Fowler and Fields, 2014). DMS data are used to evaluate
these unsupervised models and, in some cases, to train supervised models for comparison.
Interestingly, unsupervised models often outperform supervised models at mutational effect prediction tasks, particularly in zero-shot scenarios. For example, the likelihoods from language models like ESM-1v and ESM-2 are competitive mutational effect predictors across many DMS datasets (Meier et al., 2021) and across datasets of clinically relevant human disease variants (Brandes et al., 2023), though there is still room for improvement in variant effect prediction (Bromberg et al., 2024). This advantage likely stems from the unsupervised models capturing broad evolutionary information across protein families, providing a strong prior for fitness effects (Hie et al., 2024). In contrast, supervised models may overfit to assay-specific nuances, limiting their generalizability. To assess the effectiveness of these approaches, benchmark suites such as ProteinGym (Notin et al., 2024) and FLIP (Fitness Landscape Inference for Proteins; Dallago et al., 2021) compile diverse DMS datasets, allowing for comprehensive evaluation of predictive models across various proteins and experimental conditions.
Predicting Viral Infectivity or Escape
Building on the broader fitness-prediction applications of protein sequence models, these approaches have found critical relevance in virology. Unsupervised protein language models have shown promise in predicting viral infectivity and escape, utilizing high-throughput DMS data that measure how amino acid changes affect these properties (Haddox, Dingens, and Bloom, 2016; Haddox et al., 2018; Lee et al., 2018; Starr et al., 2020; Wu et al., 2020; Starr et al., 2022). Viral escape refers to mutations allowing viruses to evade immune responses, while infection is mediated by specific proteins interacting with host cell receptors. Initial work demonstrated that statistical properties learned by protein sequence models correspond to viral escape characteristics (Riesselman, Ingraham, and Marks, 2018; Hie et al., 2021; Thadani et al., 2023). Subsequent work showed that larger protein language models like ESM, either zero-shot or when fine-tuned on viral proteins, can competitively model various aspects of viral evolution (Hie, Yang, and Kim, 2022; Beguir et al., 2023; Ito et al., 2024; Lamb et al., 2024). These diverse methods offer promising tools for studying mutational effects on near-term infectivity or escape, but their ability to predict long-term viral evolution remains limited. Viral evolution across multiple generations and long evolutionary trajectories inherently has substantial levels of uncertainty. Better models are needed to forecast viral evolution accurately over the long term, highlighting the ongoing challenges in translating these insights into reliable vaccine design and pandemic preparedness strategies.
Notable Prediction Task 3: Multi-omic Sequence Prediction
Another notable direction in biological prediction tasks relevant to design workflows is the development of tools that infer complex genomic and epigenomic features directly from DNA sequences. Enformer (Avsec et al., 2021) predicts multiple epigenomic tracks from raw DNA sequence, capturing regulatory interactions across long genomic distances. These tracks typically include data on chromatin accessibility, histone modifications, and transcription factor binding, often measured experimentally through techniques like ATAC-seq (Assay for Transposase-Accessible Chromatin using sequencing). Extending these models, Borzoi (Linder et al., 2023) focuses on predicting gene expression tracks, which reflect the activity levels of genes across different cell types or conditions, usually measured by RNA-seq. Both models use CNN deep learning architectures to learn the intricate relationships between DNA sequence and functional genomic readouts. These approaches are valuable as they provide insights into gene regulation and expression without requiring extensive experimental data when given new DNA sequences, and are therefore used as part of DNA regulatory element design pipelines (which we review below) to evaluate if a given design produces the desired impact on the downstream epigenomic sequence. However, like other predictive models in computational biology, the predictions of these models, and subsequent designs, should be interpreted cautiously and validated experimentally when possible.
BIOLOGICAL MODELS III: DESIGN MODELS
We have so far considered foundation models that learn unsupervised information (e.g., learning the distribution of sequences) and predictive models that map sequences to functions. We now consider biological design, which benefits from combining both generative and predictive models (see Figure A-1). This section examines the landscape of machine learning–guided biological design tools; their underlying principles; and their potential to transform key processes in drug discovery, enzyme engineering, and synthetic biology. We begin with a general discussion on how advancements in both generative models and predictive models can be combined to improve biological design pipelines. As protein design has been a primary focus of biological design efforts, we then review two major categories in this field: function-guided adaptive protein design, which relies on iterative rounds of experimental testing and evaluation, and de novo protein design, which emphasizes the creation of structurally novel proteins. We conclude by exploring machine learning–guided biological design beyond protein molecules.
Generative Models, Predictive Models, and Biological Design
In the earlier section on foundation models, we described how generative models enable a user to efficiently sample from a complex data distribution. While generative models play a crucial role in biological design tasks, they are often insufficient on their own. These models learn to capture the distribution of naturally occurring biological sequences or structures, providing a foundation for generating plausible new designs. However, generating designs with specific desired functions requires additional steps. Typically, generative models are coupled with predictive models in a rejection sampling framework (Hastie et al., 2009); in this approach, the generative model proposes candidate sequences, which are then evaluated by a predictive model. Only sequences predicted to have the desired function are selected for experimental testing, while the remainder are “rejected.” This combination allows for efficient exploration of the vast sequence space while focusing on promising candidates. This strategy not only increases the likelihood of discovering sequences with desired properties but also significantly reduces the experimental burden by prioritizing the most promising candidates for laboratory validation (Hie and Yang, 2022).
Beyond rejection sampling, a predictive scoring function could be used to directly bias the generative model’s samples using algorithms like supervised fine-tuning (SFT), reinforcement learning techniques, or direct preference optimization (DPO) (Rafailov et al., 2024). SFT involves further training the generative model on a curated dataset of high-scoring sequences to shift its distribution. Reinforcement learning techniques, such as proximal policy optimization (Schulman et al., 2017; Ouyang et al., 2022), iteratively update the model to maximize a reward signal derived from the scoring function. DPO aligns the model’s outputs with desired preferences without explicit reward modeling, often using pairwise comparisons between positively and negatively labeled samples (Rafailov et al., 2024). These approaches aim to align the generative model’s output more closely with the desired functional properties, potentially increasing the efficiency of the design process compared to simple rejection sampling.
Notable Design Task 1: Function-Guided Adaptive Protein Design
Function-guided biological design specifies a desirable biological function and aims to produce a sequence that exhibits that desirable function. In recent years, adaptive machine learning approaches have emerged as powerful tools for function-guided biological design, particularly in the realm of protein engineering to navigate the vast and complex landscape of possible sequences. These methods combine computational predictions with iterative experimental validation to search efficiently for proteins with desired properties (Hie and Yang, 2022).
At the heart of many of these approaches is Bayesian optimization, a strategy for finding the global optimum of an unknown function. In the context of protein engineering, this function might map protein sequences to a desired property like enzyme activity or stability. Bayesian optimization typically uses a probabilistic surrogate model, often a Gaussian process, to approximate this unknown function (Rasmussen and Williams, 2005). Gaussian processes are flexible, nonparametric models that can capture complex relationships and provide uncertainty estimates for their predictions.
The optimization process iterates between using the surrogate model to select promising candidates and experimentally testing these candidates to refine the model. This selection is guided by an acquisition function, which balances the exploitation of designs predicted to be good with the exploration of uncertain regions of the sequence space. A common acquisition function is the upper confidence bound, which combines the predicted value with the uncertainty of that prediction (Rasmussen and Williams, 2005). Several studies have used Gaussian process predictions and uncertainty estimates to guide iterative rounds of experiments (Romero, Krause, and Arnold, 2013; Hie, Bryson, and Berger, 2020; Greenhalgh et al., 2021).
Generative models, such as VAEs or protein language models, are often used to propose new candidate sequences. These models can learn the distribution of valid protein sequences and generate novel sequence designs that can then be tested for functional activity. For example, Madani and colleagues (2023) use an autoregressive protein language model to generate lysozyme proteins with active catalytic activity and as low as 40 percent sequence identity to natural lysozymes. Similarly, Hayes and colleagues (2024) use a masked language model combined with rounds of experimental data collection to design a green fluorescent protein (GFP) homolog with less than 60 percent sequence identity to natural GFPs.
Adaptive sampling techniques can further refine these generative models based on the results of the surrogate model, steering the generation process toward more promising regions of the sequence space. A key advantage of these methods is their ability to learn and improve over multiple rounds of experimentation. This iterative process, sometimes called active learning, allows the models to become increasingly accurate and efficient at identifying promising designs (Hie and Yang, 2022).
Because active learning often requires multiple rounds of experimental data collection, a recent trend has been to augment these processes with automated experimental platforms. For example, Rapp, Bremer, and Romero (2024) use multiple rounds of Bayesian optimization with a Gaussian process combined with an experimental pipeline with a heavy use of automation to design a suite of more active enzymes. These approaches could accelerate the design-build-test cycle in biological engineering, but
laboratory automation pipelines are still difficult to set up and are less reliable for more complex biological assays. While relatively robust binding measurements or enzymatic activity assays are amenable to laboratory automation in the immediate term, improvements in laboratory automation technologies could improve the generalizability of this approach.
Other challenges to function-guided adaptive learning strategies remain. Protein sequences are discrete and high-dimensional, which can pose difficulties for traditional optimization techniques. Additionally, biological experiments often involve large batch sizes and limited rounds of testing, which require careful consideration in the design of optimization strategies. Despite these challenges, adaptive machine learning approaches are becoming a more regular part of a protein engineering pipeline.
Notable Design Task 2: Structure-Guided De Novo Protein Design
While adaptive machine learning techniques have been developed mainly to enhance existing proteins through iterative rounds of experimentation, structure-guided “de novo design” aims to create entirely new proteins using computational methods with structures that are substantially different from the structures of natural proteins (Chu, Lu, and Huang, 2024). The sophistication of de novo design has increased by replacing early approaches based on physical principles with recent advances in machine learning.
The modern protein design workflow often uses a two-step process. First, structure generation models like RFdiffusion (Watson et al., 2023) create protein backbones, allowing designers to specify constraints such as binding interfaces or symmetry. Then, inverse folding methods like ProteinMPNN (Dauparas et al., 2022) or ESM-IF1 (Hsu, Verkuil, et al., 2022) determine amino acid sequences likely to fold into the generated structures. Designs are typically evaluated using a “self-consistency” metric, which assesses whether a designed sequence is likely to fold into the intended structure under a structure prediction model like AlphaFold or ESMFold.
De novo protein design to engineer proteins with useful functions, in addition to novel structures, typically still uses parts of natural proteins that are involved in a specific function (e.g., an enzyme active site or a binding interface) but replaces other components of the protein with a nonnatural protein scaffold. These developments have enabled the creation of de novo proteins with complex functions, including enzymes, protein binders, and designed proteins that can form large assemblies or span cell membranes (Courbet et al., 2022; Wang et al., 2022; Watson et al., 2023).
While progress has been substantial, challenges remain, particularly in areas where fine control over chemical interactions and conformational dynamics is crucial. The field is moving toward more integrated approaches
that consider multiple states, dynamics, and the co-design of sequence and structure (Chu, Lu, and Huang, 2024). Future advancements likely will come from a combination of data-driven approaches and first-principles reasoning (e.g., directly incorporating biophysical principles or experimental data into protein design tools), potentially leading to greater versatility of de novo designed proteins.
Other Design Tasks
Machine learning–guided biological design has extended beyond proteins to other biological modalities, albeit to a more limited extent. One notable example is the work by Nguyen and colleagues, who developed a genomic language model, Evo, that learns sequence information underlying DNA, RNA, and proteins from raw genome sequences (Nguyen, Poli, Durrant, et al., 2024). This model enables the design of multimodal biological systems, including CRISPR-Cas systems (involving protein-RNA co-design) and transposon systems (focusing on protein-DNA co-design). Another notable area is machine learning–guided promoter design, which is often used in synthetic biology applications to control levels of gene expression in E. coli or to control cell-type-specific gene expression in mouse or human cells (LaFleur, Hossain, and Salis, 2022; Zhang et al., 2023; DaSilva et al., 2024; Reddy et al., 2024). The approach here parallels that of protein design: either a generative model produces promoter sequences, or a large collection of promoters is utilized as a starting point. These candidate promoters are then evaluated using a promoter activity prediction model. The designs are subsequently tested in the laboratory, with the results feeding back into the system to refine future predictions and designs. This iterative process allows for continuous improvement in the design of promoters with desired activities. As generative and predictive machine learning models improve, we can expect to see further integration of machine learning across various aspects of biological design, potentially leading to more efficient approaches to engineering biological systems.
BIOLOGICAL DATASETS
Biological datasets are crucial for training foundation models, as they provide the raw material from which these models learn complex patterns. When training foundation models by leveraging the scaling hypothesis, the scale, quality, and complexity of data are as important as the model size and the amount of compute used to train the model (Kaplan et al., 2020; Hoffmann et al., 2022). This review focuses on large-scale public datasets representing a diverse range of biological data types, including genetic sequence data (spanning proteins, RNA, DNA, and whole genomes),
molecular structures, molecular properties, epigenomic information, and transcriptomic data, which we also describe in Table A-3. We also summarize ways to link information across multiple modalities when training multimodal language models.
Genetic Sequence Datasets
Genome Sequence
Genomic sequencing data form the foundation for databases of proteins, RNAs, and regulatory DNA sequences. Most genome sequences are obtained through shotgun sequencing, where short DNA fragments are sequenced, quality-filtered, and assembled into longer contiguous sequences called contigs. These contigs can be derived from a single species’ genomic DNA (or RNA for some viruses) or from mixed species samples (metagenomic data) (Giani et al., 2020). Bioinformatic tools then identify potential genes, protein-coding sequences, and other functional elements, though annotation quality can vary by species (Yandell and Ence, 2012). The primary repositories for these genomic sequences and annotations are GenBank from the National Center for Biotechnology Information (NCBI) (Sayers et al., 2019) in the United States and the European Nucleotide Archive (ENA) from EMBL-EBI.2 Specialized databases often curate subsets of NCBI and ENA data and offer additional metadata. For instance, RefSeq is a high-quality subset of NCBI genome data with annotations (O’Leary et al., 2016); the Ensembl and EnsemblGenomes databases likewise curate ENA genomes along with annotations (Yates et al., 2022; Martin et al., 2023), while the Genome Taxonomy Database (GTDB) focuses on high-quality prokaryotic genomes (Parks et al., 2022). Specialized protein and RNA sequence databases also heavily leverage the annotated sequences in these larger genomic sequence databases. Metagenomics databases, which are often also deposited into NCBI or ENA, include the following: Unified Human Gastrointestinal Genome (UHGG) (Almeida et al., 2021), Joint Genome Institute Integrated Microbial Genomes (JGI IMG) (Markowitz et al., 2006), Human Gastrointestinal Bacteria Genome Collection (Forster et al., 2019), MGnify (Richardson et al., 2023), Youngblut and colleagues’ (2020) animal gut metagenomes, and the Tara Oceans Project (Pesant et al., 2015). Genomic sequence models often train on a much smaller subset of the terabytes of sequences found in these databases. Many genomic sequence models have only been applied to the human reference genome. Evo, a genomic language model trained on prokaryotic genomes, was mostly trained on GTDB.
___________________
2 See https://www.ebi.ac.uk/ena/ (accessed November 17, 2024).
TABLE A-3 Biological Databases
| Category | Database name | Type of data stored | Citation or URL |
|---|---|---|---|
| Genome sequence | GenBank | Genomic sequences and annotations | Sayers et al., 2019 |
| Genome sequence | European Nucleotide Archive (ENA) | Genomic sequences and annotations | https://www.ebi.ac.uk/ena/browser/home |
| Genome sequence | RefSeq | Genomic sequences and annotations | O’Leary et al., 2016 |
| Genome sequence | Ensembl | Genomic sequences and annotations | Martin et al., 2023 |
| Genome sequence | Ensembl Genomes | Genomic sequences and annotations | Yates et al., 2022 |
| Genome sequence | Genome Taxonomy Database (GTDB) | Prokaryotic genome sequences | Parks et al., 2022 |
| Genome sequence | Unified Human Gastrointestinal Genome (UHGG) | Metagenomic sequences | Almeida et al., 2021 |
| Genome sequence | JGI IMG | Microbial genome and metagenome sequences | Markowitz et al., 2006 |
| Genome sequence | Human Gastrointestinal Bacteria Genome Collection | Gut microbiome metagenomic sequences | Forster et al., 2019 |
| Genome sequence | MGnify | Metagenomic sequences | Richardson et al., 2023 |
| Genome sequence | Youngblut et al. | Animal gut metagenomic sequences | Youngblut et al., 2020 |
| Genome sequence | Tara Oceans Project | Marine metagenomic sequences | Pesant et al., 2015 |
| Protein sequence | UniProt | Protein sequences and annotations | UniProt Consortium, 2019 |
| Protein sequence | UniRef50/UniRef90 | Clustered protein sequences | Suzek et al., 2007 |
| Protein sequence | Pfam | Protein domain sequences and annotations | El-Gebali et al., 2019 |
| Protein sequence | Observed Antibody Space (OAS) | Antibody variable region sequences | Olsen, Boyles, and Deane, 2022 |
| Viral sequence | GISAID | Influenza and SARSCoV-2 sequences | Shu and McCauley, 2017 |
| Viral sequence | BV-BRC | Bacterial and viral sequences | Olson et al., 2023 |
| Category | Database name | Type of data stored | Citation or URL |
|---|---|---|---|
| Viral sequence | Influenza Research Database | Influenza virus sequences | Zhang et al., 2017 |
| Viral sequence | LANL HIV database | HIV sequences | Foley et al., 2018 |
| Noncoding RNA sequence | Rfam | RNA family sequences | Kalvari et al., 2021 |
| Noncoding RNA sequence | RNAcentral | Noncoding RNA sequences | Sweeney et al., 2019 |
| Biomolecular structure | Protein Data Bank (PDB) | 3D structures of biological macromolecules | Berman et al., 2000 |
| Biomolecular structure | CATH | Protein domain structures and classifications | Knudsen and Wiuf, 2010 |
| Biomolecular structure | CASP | Protein structure prediction targets | repasted https://predictioncenter.org/ |
| Biomolecular structure | AlphaFoldDB | Predicted protein structures | Varadi et al., 2022 |
| Biomolecular structure | ESM Metagenomic Atlas | Predicted metagenomic protein structures | Lin et al., 2023 |
| Protein function | ProteinGym | Protein mutational effect datasets | Notin et al., 2024 |
| Protein function | FLIP | Protein fitness landscape datasets | Dallago et al., 2021 |
| Protein function | ClinVar | Genetic disease variants and phenotypes | Landrum et al., 2018 |
| Protein function | SKEMPI | Protein-protein interaction affinity changes | Jankauskaitė et al., 2019 |
| Protein function | PDBbind | Biomolecular binding affinity data | Wang et al., 2005 |
| Protein function | BindingDB | Protein-small molecule interaction data | Liu et al., 2007 |
| Protein function | BRENDA | Enzyme and enzyme-ligand data | Chang et al., 2021 |
| Protein function | Binding MOAD | Protein-ligand binding data | Wagle et al., 2023 |
| Protein function | 2P2Idb | Protein-protein interactions targetable by small molecules | Basse et al., 2016 |
| Category | Database name | Type of data stored | Citation or URL |
|---|---|---|---|
| Protein function | ProThermDB | Protein stability data | Nikam et al., 2021 |
| Protein function | STITCH | Protein-chemical interactions | Szklarczyk et al., 2016 |
| Protein function | DrugBank | Drug-target interactions | Knox et al., 2011 |
| Protein function | Gene Ontology (GO) | Gene and protein function annotations | Aleksander et al., 2023 |
| Epigenomic datasets | ENCODE | Epigenomic data for human and mouse | ENCODE Project Consortium, 2012 |
| Epigenomic datasets | Roadmap Epigenomics Project | Human epigenomic data | Kundaje et al., 2015 |
| Epigenomic datasets | PsychENCODE | Brain epigenome data | Akbarian et al., 2015 |
| Epigenomic datasets | 4D Nucleome Project | 3D genome organization data | Dekker et al., 2017 |
| Epigenomic datasets | FANTOM | Transcription start sites and enhancers | Andersson et al., 2014 |
| Transcriptomic datasets | Human Cell Atlas (HCA) | Human single-cell transcriptomic data | Regev et al., 2017 |
| Transcriptomic datasets | Tabula Sapiens | Human single-cell transcriptomic data | Jones et al., 2022 |
| Transcriptomic datasets | Tabula Muris | Mouse single-cell transcriptomic data | The Tabula Muris Consortium, 2018 |
| Transcriptomic datasets | Fly Cell Atlas | Fruit fly single-cell transcriptomic data | Li et al., 2022 |
| Transcriptomic datasets | CELLxGENE | Aggregated single-cell data | CZI Single-Cell Biology Program et al., 2023 |
| Transcriptomic datasets | Broad Single Cell Portal | Aggregated single-cell data | https://singlecell.broadinstitute.org/single_cell |
NOTE: This table provides an overview of major biological databases related to biological model training, organized by category of biological data. It includes databases for genome sequences, protein sequences, coding and noncoding RNA sequences, biomolecular structures, protein functions, epigenomic data, and transcriptomic data. For each database, we provide a brief description of the type of data stored. Datasets of sufficient diversity and quality to train foundation models are highlighted in light blue.
TABLE A-4 Example Training Datasets and Associated Models
| Model | Model type | Training datasets |
|---|---|---|
| ESM-2 | Protein sequence model | UniRef90 |
| Evo | Genomic sequence model | GTDB, IMG/PR, IMG/VR |
| AlphaFold2 | Structure prediction model | PDB |
| ProGen2 | Protein sequence model | UniRef90, metagenomic sequences, Observed Antibody Space (OAS) |
| AbLang | Antibody protein sequence model | Observed Antibody Space (OAS) |
| CaLM | Codon sequence model | Coding sequences from European Nucleotide Archive (ENA) |
| RiNALMo | Noncoding RNA sequence model | Rfam, RNAcentral, NCBI |
| GenSLM | Genomic sequence model | GenBank |
| Enformer | Multi-omic prediction model | ENCODE datasets |
| scGPT | Transcriptomic count model | CELLxGENE |
NOTE: Example models and their corresponding training datasets. These datasets are typical for each of the types of models in the table. Some models draw from multiple publicly available data sources for training.
Protein Sequence
Protein sequence datasets are primarily sourced from UniProt (Universal Protein Resource), which is a high-quality database that includes many manually annotated and experimentally validated sequences (UniProt Consortium, 2019). UniRef50 and UniRef90 provide clustered versions of UniProt at 50 percent and 90 percent sequence identity thresholds, respectively, which removes redundant proteins to ensure that protein language models are trained on diverse sequences (Suzek et al., 2007). Another highly curated protein database is Pfam, which uses hidden Markov models to identify and classify recurring structural and functional units within proteins; all protein sequences in Pfam have an associated Pfam domain categorization (El-Gebali et al., 2019). Metagenomics databases such as MGnify (Richardson et al., 2023) and databases maintained by the Joint Genome Institute (JGI) (Markowitz et al., 2006) identify potential protein sequences from prokaryotic genomes by locating open reading frames, which are DNA sequences between start and stop codons that potentially encode proteins. While potentially lower quality than UniProt, metagenomic databases help to expand the known protein sequence space greatly. Antibody language models primarily make use of the Observed Antibody Space (OAS) dataset (Olsen, Boyles, and Deane, 2022), containing ~2 billion antibody variable domain sequences. Viral protein language models use protein sequences identified during viral surveillance (primarily directed at the highly mutable
pandemic viruses such as influenza A, HIV, and severe acute respiratory syndrome coronavirus 2 [SARS-CoV-2]) and deposited into databases such as NCBI RefSeq (O’Leary et al., 2016), GISAID (Global Initiative on Sharing All Influenza Data) (Shu and McCauley, 2017), the Bacterial and Viral Bioinformatics Resource Center (BV-BRC) database (Olson et al., 2023), Influenza Research Database (Zhang et al., 2017), and the Los Alamos National Laboratory (LANL) HIV database (Foley et al., 2018).
Coding RNA Sequence
Codon language models are trained on coding sequences extracted from natural genomes, utilizing the coding sequence annotations found in NCBI or ENA databases. In prokaryotic genomes, these coding sequences are contiguous. However, in eukaryotic genomes, coding sequences are noncontiguous due to the presence of introns. Eukaryotic gene expression involves splicing, a process in which introns are removed and exons are joined to form the mature mRNA. Thus, eukaryotic coding sequence datasets require annotations specifying which genomic regions are retained in the final transcript. Notable codon language models include CaLM, which is trained on coding sequences from ENA, and CodonBERT, which utilizes coding sequences from NCBI (Outeiral and Deane, 2024; Ren et al., 2024).
Noncoding RNA Sequence
Several language models are specifically trained on ncRNA sequences. As with protein coding sequences, many ncRNA sequences are derived from annotated ncRNA data in GenBank and Ensembl, and eukaryotic ncRNA sequences must account for splicing. Additional ncRNA-specific databases include Rfam (Kalvari et al., 2021), which organizes ncRNA sequences into RNA families (analogous to Pfam for proteins), and RNAcentral (Sweeney et al., 2019), a comprehensive collection of ncRNAs that incorporates sequences from various sources, including GenBank and Ensembl.
Biomolecular Structure Datasets
Decades of experimental work in structural biology, resulting in large curated datasets of molecular structures, have been instrumental in driving the progress in biomolecular structure prediction represented by AlphaFold. The Protein Data Bank (PDB) serves as the primary repository for experimentally determined 3D structures of biological macromolecules, including proteins and nucleic acids (Berman et al., 2000). The structures in the PDB are primarily determined through experimental methods such as X-ray crystallography, nuclear magnetic resonance (NMR) spectroscopy, and
cryo-EM. X-ray crystallography provides high-resolution structures by analyzing X-ray diffraction patterns from protein crystals. NMR spectroscopy determines structures in solution, offering insights into protein dynamics. Cryo-EM, which has seen significant recent advancements, images flash-frozen proteins using electron microscopy, allowing for the determination of large complex structures and conformational states.
Many additional datasets are built off of data that have been deposited in the PDB. CATH (Class, Architecture, Topology, Homology) offers a hierarchical classification of protein domains based on their 3D structures, organizing PDB entries into structurally related groups (Knudsen and Wiuf, 2010). CASP (Critical Assessment of protein Structure Prediction)3 is a biannual competition that assesses the state of the art in protein structure prediction method; as part of CASP, new protein structures are experimentally determined and used as a test set for structure prediction models. Both CATH and CASP are particularly valuable for developing machine learning models for structural biology, as they provide splits of protein structures based on structural similarity and, in the case of CASP data, temporally held-out data with respect to different versions of the PDB. Ensuring proper held-out structures during model development helps mitigate data leakage, a common issue in machine learning where information from the test set inadvertently influences the training process, leading to overly optimistic performance estimates. By using structural similarity-based splits, researchers can more accurately assess generalization capabilities to new protein folds.
A more recent development in structural biology is the emergence of large databases of AI-generated protein structure predictions. AlphaFoldDB contains AlphaFold2-predicted structures for nearly all proteins in UniProt, representing ~214 million structure predictions (Varadi et al., 2022). Another database, the ESM Metagenomic Atlas, provides predicted structures for more than 617 million metagenomic proteins using the ESMFold structure prediction method (Lin et al., 2023). This atlas extends structural coverage to diverse microbial proteins from various environments. While these databases can be useful for providing structural hypotheses for many natural proteins and potentially for augmenting machine learning models that require large amounts of structural training data, they should also be treated with increased caution. The best-performing models that incorporate protein structure during training still mainly utilize experimental structure data, with some mixture of predicted structure data.
___________________
3 See https://predictioncenter.org/ (accessed November 17, 2024).
Protein Function Datasets
Large datasets that map many protein sequences to an associated fitness value (where fitness is defined as the strength of some function-of-interest and which is typically tied to some kind of experimental assay) are useful for both model evaluation and development. Here, we use definitions common in the directed evolution literature in which a “function” is defined as a particular biological property or process (e.g., stability, catalysis, binding) and “fitness” is defined as how well or strongly the protein achieves that function (e.g., scoring a variant by melting temperature, Michaelis-Menten kinetics, or binding affinity). As described in the section above on biological foundation models, many biological sequence models are evaluated based on their ability to predict mutational effects on fitness, which is done by correlating the fitness score of a given mutation with the language model likelihood assigned to that mutation. Protein fitness datasets are also used to develop models that predict functional activity from the protein sequence; these models can then be used as part of an adaptive machine learning loop for machine learning–guided directed evolution and iterative protein design. More recently, these datasets are also being used to align protein generative models so that sampling from these models results in more desirable designs.
High-throughput protein measurement techniques often use cellular expression systems with sorting or selection methods (Fowler et al., 2010; Jacquier et al., 2013). Cell surface display technologies, such as yeast display, express proteins on cell surfaces for easy measurement, often using flow cytometry to quantify expression and binding. Likewise, intracellular expression coupled with fluorescent reporters enables fluorescence-activated cell sorting to isolate desired variants. Some techniques use cell viability or fitness as a readout, linking protein function to cell survival or growth rate for selection through competition or survival experiments. Other high-throughput methods for collecting many protein fitness measurements are based on microfluidics; for example, the HT-MEK platform uses droplet-based microfluidics to perform thousands of individual enzyme assays in parallel at nanoliter scale (Markin et al., 2021). When a study measures an exhaustive set of mutations to a protein—for example, all single-residue substitutions—the study is referred to as a deep mutational scan (DMS) (Fowler and Fields, 2014).
Phage and yeast display apply these principles to study antibody–antigen interactions, expressing antibody variants on bacteriophage or yeast surfaces, followed by incubation with a solution containing the antigen (Hunter and Cochran, 2016). These systems enable rapid screening of large collections of antibody sequences, isolating high-affinity binders through multiple selection rounds. High-throughput methods based on cell-based assays followed by nucleotide sequencing are also used to identify viral
protein variants with increased infectivity or antibody escape. This involves creating mutated viral or pseudoviral particles (often modified so that they cannot replicate), optionally exposing them to antibody selection pressure, infecting cells, and sequencing the more successful viral variants. This approach allows for high-throughput assessment of viral mutations that impact infectivity or immune evasion (Haddox, Dingens, and Bloom, 2016; Haddox et al., 2018; Lee et al., 2018; Starr et al., 2020; Wu et al., 2020; Starr et al., 2022).
Other large-scale protein fitness datasets increase the scope of data collected via laboratory automation, large-scale manual effort, or a combination of both. For example, Cao and colleagues (2022) were able to collect neutralization data representing 2,096 mutations to the receptor binding domain of the SARS-CoV-2 spike protein in the presence of 1,548 antibodies, representing a total of 173,384 neutralization measurements. While impressive in scope, fitness data collection at this scale still requires substantial human resources beyond what can be accomplished by laboratory automation alone.
Unlike protein structure data, there is no single comprehensive database that systematically curates large-scale protein fitness data. Often, these data are simply included as supplementary information in research publications. Some initiatives have aimed to consolidate DMS datasets into standardized formats with consistent preprocessing, primarily to serve as benchmark evaluation sets for comparing protein language models. Notable examples include ProteinGym (Notin et al., 2024), a collection curated by Livesey and Marsh (2020), and the FLIP dataset collection (Dallago et al., 2021). In addition to DMS data, ProteinGym incorporates human genetic variants commonly associated with disease from the ClinVar database (Landrum et al., 2018), further enhancing its utility for model evaluation and development. However, additional effort is most likely needed to curate protein fitness datasets more consistently across many high-throughput studies.
Beyond DMS datasets, there are some databases specific to certain kinds of protein function. In particular, several databases have been developed to curate and provide access to protein binding data, serving as valuable resources for understanding protein–protein and protein–ligand interactions. SKEMPI (Structural Kinetic and Energetic database of Mutant Protein Interactions) focuses on experimentally determined binding affinity changes upon mutation for protein–protein interactions (Jankauskaitė et al., 2019). PDBbind offers a comprehensive collection of experimentally measured binding affinity data for biomolecular complexes found in the PDB (Wang et al., 2005). BindingDB provides data on protein interactions with small drug-like molecules (Liu et al., 2007), while BRENDA, primarily an enzyme database, includes enzyme-ligand binding information (Chang et al., 2021). Other notable resources include Binding MOAD (Mother of
All Databases) (Wagle et al., 2023), 2P2Idb for protein–protein interactions targetable by small molecules (Basse et al., 2016), and ProThermDB for protein stability data (Nikam et al., 2021). Additionally, STITCH integrates various sources of protein-chemical interactions (Szklarczyk et al., 2016), while DrugBank, primarily a drug database, contains extensive information on drug-target interactions (Knox et al., 2011).
Finally, there are some databases that map protein sequences to standardized functional descriptions in natural language. Gene Ontology (GO) provides a structured vocabulary categorizing gene and protein functions into molecular function, biological process, and cellular component, with a hierarchical structure allowing varied detail (Aleksander et al., 2023). UniProt contains comprehensive protein information, including function descriptions, catalytic activities, cofactors, regulation, structure, and pathway involvement, while also incorporating GO annotations. These systems enable translation of sequence data into functional descriptions, or vice versa, and can be used to connect protein generative models with LLMs.
Epigenomic Datasets
Many predictive models have attempted to predict epigenomic tracks from DNA sequence, leveraging the wealth of data generated by various epigenomic sequencing technologies. These technologies provide insights into chromatin structure, DNA modifications, and 3D genome organization, offering a comprehensive view of the functional state of the genome beyond its primary sequence.
ATAC-seq identifies open chromatin regions by inserting sequencing adapters into accessible areas of the genome (Buenrostro et al., 2013). This method has become increasingly popular due to its simplicity and effectiveness in mapping regulatory regions. DNA methylation, another crucial epigenetic modification, can be measured through various techniques such as bisulfite sequencing, which provides single-base resolution methylation maps, or MeDIP-seq, which uses immunoprecipitation to capture methylated DNA fragments (Greenberg and Bourc’his, 2019). Hi-C (High-throughput chromosome conformation capture) offers insights into the 3D organization of the genome by capturing long-range chromatin interactions (Lieberman-Aiden et al., 2009).
The ENCODE (Encyclopedia of DNA Elements) project is a large source of epigenomic data for human and mouse genomes (ENCODE Project Consortium, 2012). This resource includes data from various assays, such as chromatin accessibility (ATAC-seq, DNase-seq), histone modifications (ChIP-seq for various histone marks), transcription factor binding sites, DNA methylation, RNA-seq for gene expression, and 3D chromatin interactions. The standardized high-quality datasets provided by ENCODE
across multiple cell types and tissues serve as the primary current resource for developing and benchmarking predictive models of epigenomic features.
Beyond ENCODE, other major epigenomic datasets and projects complement its efforts. The Roadmap Epigenomics Project has mapped epigenomic landscapes across a wide range of human cell types and tissues (Kundaje et al., 2015). More specialized projects include PsychENCODE (Akbarian et al., 2015), which maps the brain epigenome with emphasis on neuropsychiatric disorders, and the 4D Nucleome Project (Dekker et al., 2017), which explores the 3D organization of the nucleus. The FANTOM project provides extensive data on transcription start sites and enhancers (Andersson et al., 2014). While these diverse projects collectively provide a rich landscape of epigenomic data across various biological contexts, cell types, and organisms, many of these datasets have yet to be fully utilized in machine learning modeling efforts.
Single-Cell Transcriptomic Datasets
scRNA-seq aims to obtain a more accurate representation of cellular heterogeneity by enabling gene expression profiling at individual cell resolution. scRNA-seq is often compared to bulk RNA sequencing, which measures averaged expression levels over a sample containing multiple cell populations, potentially masking important cell-type-specific variation. scRNA-seq data are typically collected by isolating individual cells using microfluidic devices, followed by sequencing of cellular mRNA. Large-scale “cell atlas” efforts, such as the Human Cell Atlas (HCA) (Regev et al., 2017) and Tabula Sapiens (Jones et al., 2022), aim to create comprehensive reference maps of all human cell types across multiple tissues and organs. Other large-scale scRNA-seq atlases have also been created for other model organisms include the Tabula Muris (The Tabula Muris Consortium, 2018) in mice and the Fly Cell Atlas (Li et al., 2022) in fruit flies. To facilitate access to these diverse datasets, centralized resources like the CELLxGENE database (CZI Single-Cell Biology Program et al., 2023) and the Broad Single Cell Portal4 have been developed. These platforms allow researchers to explore, analyze, and download single-cell data from multiple studies, providing interactive visualization tools and basic analysis capabilities. These atlas-level datasets make up the bulk of the training data for single-cell foundation models.
___________________
4 See https://singlecell.broadinstitute.org/single_cell (accessed November 17, 2024).
LARGE LANGUAGE MODELS AND BIOLOGICAL INTEGRATION
Integrating LLMs like GPT and Claude with biological design tools represents an emerging area of research. This integration could leverage the rich representations and reasoning capabilities of LLMs alongside the specialized knowledge encoded in biological data–specific models. Early efforts in this field show promise, though many technological challenges remain.
Some efforts focus on creating AI co-pilots for bioinformatics or drug discovery, integrating LLMs with tools like BLAST for sequence similarity searches or genome annotation software. These systems aim to enhance the efficiency and accuracy of bioinformatics workflows by providing intelligent assistance to researchers. Most of the efforts are carried out in the private sector; for example, LOWE by Valence Labs is a scientific co-pilot for bioinformatic tool usage in pharmaceutical companies.5 More general-purpose software co-pilots like Devin by Cognition6 have also been demonstrated for their biology-specific applications.
Another avenue of exploration involves generating protein sequences from natural language prompts. The aspiration is to enable users to specify functional proteins purely through natural language descriptions. For example, ESM3 contains a protein function track that also enables a user to, for example, condition sequence and structure generation given a natural language function-of-interest (Hayes et al., 2024). While potentially promising, this approach may be limited by the number of proteins with comprehensive natural language labels in datasets like UniProt.
Perhaps the most ambitious efforts involve directly connecting LLMs with laboratory experimental feedback. Proposals for “cloud labs” envision remote users (or potentially LLMs themselves) writing programs to specify experimental protocols, which are then executed in automated laboratory environments.7 The resulting data would be fed back to the user or LLM for analysis, new hypothesis generation, and experimental planning. While this concept is tantalizing, it does face substantial near-term challenges. Current cloud labs struggle with complex biological workflows and are currently limited mainly to inorganic chemistry applications (Abolhasani and Kumacheva, 2023) or basic liquid handling. Furthermore, LLMs would likely require substantial improvements in scientific knowledge, reasoning capabilities, and long-term planning to effectively manage such systems.
Despite these challenges, the integration of LLMs with biological design tools holds substantial potential for accelerating scientific discovery and innovation in the life sciences. As both LLM capabilities and biological automation continue to advance, we can anticipate increasingly
___________________
5 See https://www.valencelabs.com/blog-posts/lowe (accessed November 17, 2024).
6 See https://www.cognition.ai/blog/introducing-devin (accessed November 17, 2024).
7 See https://www.futurehouse.org/ (accessed November 17, 2024).
sophisticated and powerful systems that can be integrated with human scientific input to advance biological discovery and design.
DISCUSSION
This work presents a comprehensive overview of the current landscape of biological machine learning models and datasets, highlighting several key themes and trends in the field. The past four years have witnessed an extraordinary acceleration in the development of AI models for biological applications. This period has seen the emergence of numerous foundation models across protein sequences, genomic sequences, and cellular transcriptomes, alongside significant advancements in predictive models such as AlphaFold2. The pace of development has been remarkable, with new models often surpassing their predecessors within months (see Figure A-2). This rapid progress, driven by increasing computational resources, larger datasets, and architectural innovations, demonstrates the field’s dynamic nature and the potential for AI to affect many areas of biology. However, this pace also presents challenges in model evaluation, reproducibility, and the continuous adaptation of downstream applications. The taxonomy of models discussed can be broadly categorized into four interconnected types: foundation models, generative models, predictive models, and design models.
Foundation models, trained on large-scale biological datasets using unsupervised objectives, learn to capture the underlying distributions of biological data. These models, exemplified by protein language models like ESM and genomic language models like Evo, demonstrate remarkable generalist capabilities across various downstream tasks. Generative models, often built upon or closely related to foundation models, enable efficient sampling from learned biological distributions and have shown particular promise in generating novel protein sequences and structures. Predictive models, on the other hand, focus on mapping between different biological modalities, such as predicting protein structure from sequence (e.g., AlphaFold) or inferring epigenomic features from DNA sequence (e.g., Enformer). Finally, design models leverage both generative and predictive capabilities to produce biological entities with desired properties, as seen in protein engineering and promoter design tasks.
Throughout this review, protein tasks are a primary focus of modern deep learning applications in biology. This emphasis is likely due to the availability of large high-quality datasets and the immediate practical applications in areas such as drug discovery and enzyme engineering. However, the field is expanding to encompass other biological modalities. Genomic sequence modeling, while currently less mature, shows promise for advancing our understanding of gene regulation and expression and enabling
NOTES: Notable models (see Tables A-1 and A-2) arranged according to their broad categories and the time of the last archival work describing the model (either the preprint date if no journal publication followed, or the date of the final journal publication). On this timeline, a burst of model development occurred at the level of protein sequence and structure prediction in 2021 and 2022. More recent modeling has focused on models of genome sequence, transcriptome counts, or generative protein models.
multimodal and multiscale design tasks. Similarly, single-cell transcriptomics modeling is an emerging area with potential for revealing insights into cellular heterogeneity and developmental processes. As more comprehensive datasets become available and model architectures continue to evolve, we can expect significant advancements in these areas.
The integration of LLMs with biology-specific tools represents an exciting frontier in the field. While still in its early stages, this integration holds the potential to enhance bioinformatics workflows, facilitate natural language–guided protein design, and potentially automate aspects of the experimental process through cloud laboratories. However, significant challenges remain in terms of model capabilities, data integration, and experimental automation.
Looking forward, the continued development of AI-enabled biological models holds immense promise for both biological design and scientific discovery. We can anticipate more sophisticated approaches to engineering proteins, genetic circuits, and other biological systems, potentially accelerating drug discovery, improving enzyme engineering, and facilitating the development of novel synthetic biological systems. These models also have the potential to reveal new biological insights by capturing complex patterns within large-scale data, as demonstrated by protein language models’ ability to provide insights into protein folding and function. However, it is crucial to view these models as tools to augment and accelerate biological research that work alongside experimental approaches. The complexity of biological systems necessitates continued experimental validation and rigorous scrutiny of AI-generated hypotheses. As the field evolves, integrating more sophisticated models with experimental workflows, we should expect substantial advancements in both basic biological science and applied biotechnology.
REFERENCES
Abolhasani, M., and E. Kumacheva. 2023. “The rise of self-driving labs in chemical and materials sciences.” Nature Synthesis 2:483–492. https://doi.org/10.1038/s44160-022-00231-0.
Abramson, J., J. Adler, J. Dunger, R. Evans, T. Green, A. Pritzel, O. Ronneberger, L. Willmore, A. J. Ballard, J. Bambrick, S. W. Bodenstein, D. A. Evans, C.-C. Hung, M. O’Neill, D. Reiman, K. Tunyasuvunakool, Z. Wu, A. Žemgulytė, E. Arvaniti, C. Beattie, O. Bertolli, A. Bridgland, A. Cherepanov, M. Congreve, A. I. Cowen-Rivers, A. Cowie, M. Figurnov, F. B. Fuchs, H. Gladman, R. Jain, Y. A. Khan, C. M. R. Low, K. Perlin, A. Potapenko, P. Savy, S. Singh, A. Stecula, A. Thillaisundaram, C. Tong, S. Yakneen, E. D. Zhong, M. Zielinski, A. Žídek, V. Bapst, P. Kohli, M. Jaderberg, D. Hassabis, and J. M. Jumper. 2024. “Accurate structure prediction of biomolecular interactions with AlphaFold 3.” Nature 630:493–500. https://doi.org/10.1038/s41586-024-07487-w.
Akbarian, S., C. Liu, J. A. Knowles, F. M. Vaccarino, P. J. Farnham, G. E. Crawford, A. E. Jaffe, D. Pinto, S. Dracheva, D. H. Geschwind, J. Mill, A. C. Nairn, A. Abyzov, S. Pochareddy, S. Prabhakar, S. Weissman, P. F. Sullivan, M. W. State, Z. Weng, M. A. Peters, K. P. White, M. B. Gerstein, A. Amiri, C. Armoskus, A. E. Ashley-Koch, T. Bae, A. Beckel-Mitchener, B. P. Berman, G. A. Coetzee, G. Coppola, N. Francoeur, M. Fromer, R. Gao, K. Grennan, J. Herstein, D. H. Kavanagh, N. A. Ivanov, Y. Jiang, R. R. Kitchen, A. Kozlenkov, M. Kundakovic, M. Li, Z. Li, S. Liu, L. M. Mangravite, E. Mattei, E. Markenscoff-Papadimitriou, F. C. P. Navarro, N. North, L. Omberg, D. Panchision, N. Parikshak, J. Poschmann, A. J. Price, M. Purcaro, T. E. Reddy, P. Roussos, S. Schreiner, S. Scuderi, R. Sebra, M. Shibata, A. W. Shieh, M. Skarica, W. Sun, V. Swarup, A. Thomas, J. Tsuji, H. van Bakel, D. Wang, Y. Wang, K. Wang, D. M. Werling, A. J. Willsey, H. Witt, H. Won, C. C. Y. Wong, G. A. Wray, E. Y. Wu, X. Xu, L. Yao, G. Senthil, T. Lehner, P. Sklar, and N. Sestan. 2015. “The PsychENCODE project.” Nature Neuroscience 18:1707–1712. https://doi.org/10.1038/nn.4156.
Aleksander, S. A., J. Balhoff, S. Carbon, J. M. Cherry, H. J. Drabkin, D. Ebert, M. Feuermann, P. Gaudet, N. L. Harris, D. P. Hill, R. Lee, H. Mi, S. Moxon, C. J. Mungall, A. Muruganugan, T. Mushayahama, P. W. Sternberg, P. D. Thomas, K. Van Auken, J. Ramsey, D. A. Siegele, R. L. Chisholm, P. Fey, M. C. Aspromonte, M. V. Nugnes, F. Quaglia, S. Tosatto, M. Giglio, S. Nadendla, G. Antonazzo, H. Attrill, G. dos Santos, S. Marygold, V. Strelets, C. J. Tabone, J. Thurmond, P. Zhou, S. H. Ahmed, P. Asanitthong, D. Luna Buitrago, M. N. Erdol, M. C. Gage, M. Ali Kadhum, K. Y. C. Li, M. Long, A. Michalak, A. Pesala, A. Pritazahra, S. C. C. Saverimuttu, R. Su, K. E. Thurlow, R. C. Lovering, C. Logie, S. Oliferenko, J. Blake, K. Christie, L. Corbani, M. E. Dolan, H. J. Drabkin, D. P. Hill, L. Ni, D. Sitnikov, C. Smith, A. Cuzick, J. Seager, L. Cooper, J. Elser, P. Jaiswal, P. Gupta, P. Jaiswal, S. Naithani, M. Lera-Ramirez, K. Rutherford, V. Wood, J. L. De Pons, M. R. Dwinell, G. T. Hayman, M. L. Kaldunski, A. E. Kwitek, S. J. F. Laulederkind, M. A. Tutaj, M. Vedi, S.-J. Wang, P. D’Eustachio, L. Aimo, K. Axelsen, A. Bridge, N. Hyka-Nouspikel, A. Morgat, S. A. Aleksander, J. M. Cherry, S. R. Engel, K. Karra, S. R. Miyasato, R. S. Nash, M. S. Skrzypek, S. Weng, E. D. Wong, E. Bakker, T. Z. Berardini, L. Reiser, A. Auchincloss, K. Axelsen, G. Argoud-Puy, M.-C. Blatter, E. Boutet, L. Breuza, A. Bridge, C. Casals-Casas, E. Coudert, A. Estreicher, M. Livia Famiglietti, M. Feuermann, A. Gos, N. Gruaz-Gumowski, C. Hulo, N. Hyka-Nouspikel, F. Jungo, P. Le Mercier, D. Lieberherr, P. Masson, A. Morgat, I. Pedruzzi, L. Pourcel, S. Poux, C. Rivoire, S. Sundaram, A. Bateman, E. Bowler-Barnett, H. Bye-A-Jee, P. Denny, A. Ignatchenko, R. Ishtiaq, A. Lock, Y. Lussi, M. Magrane, M. J. Martin, S. Orchard, P. Raposo, E. Speretta, N. Tyagi, K. Warner, R. Zaru, A. D. Diehl, R. Lee, J. Chan, S. Diamantakis, D. Raciti, M. Zarowiecki, M. Fisher, C. James-Zorn, V. Ponferrada, A. Zorn, S. Ramachandran, L. Ruzicka, M. Westerfield, S. A. Aleksander, J. Balhoff, S. Carbon, J. M. Cherry, H. J. Drabkin, D. Ebert, M. Feuermann, P. Gaudet, N. L. Harris, D. P. Hill, R. Lee, H. Mi, S. Moxon, C. J. Mungall, A. Muruganugan, T. Mushayahama, P. W. Sternberg, P. D. Thomas, K. Van Auken, J. Ramsey, D. A. Siegele, R. L. Chisholm, P. Fey, M. C. Aspromonte, M. V. Nugnes, F. Quaglia, S. Tosatto, M. Giglio, S. Nadendla, G. Antonazzo, H. Attrill, G. dos Santos, S. Marygold, V. Strelets, C. J. Tabone, J. Thurmond, P. Zhou, S. H. Ahmed, P. Asanitthong, D. Luna Buitrago, M. N. Erdol, M. C. Gage, M. Ali Kadhum, K. Y. C. Li, M. Long, A. Michalak, A. Pesala, A. Pritazahra, S. C. C. Saverimuttu, R. Su, K. E. Thurlow, R. C. Lovering, C. Logie, S. Oliferenko, J. Blake, K. Christie, L. Corbani, M. E. Dolan, H. J. Drabkin, D. P. Hill, L. Ni, D. Sitnikov, C. Smith, A. Cuzick, J. Seager, L. Cooper, J. Elser, P. Jaiswal, P. Gupta, P. Jaiswal, S. Naithani, M. Lera-Ramirez, K. Rutherford, V. Wood, J. L. De Pons, M. R. Dwinell, G. T. Hayman, M. L. Kaldunski, A. E. Kwitek, S. J. F. Laulederkind, M. A. Tutaj, M. Vedi, S.-J. Wang, P. D’Eustachio, L. Aimo, K. Axelsen, A. Bridge, N. Hyka-Nouspikel, A. Morgat, S. A. Aleksander, J. M. Cherry, S. R. Engel, K. Karra, S. R. Miyasato, R. S. Nash, M. S. Skrzypek, S. Weng, E. D. Wong, E. Bakker, T. Z. Berardini, L. Reiser, A. Auchincloss, K. Axelsen, G. Argoud-Puy, M.-C. Blatter, E. Boutet, L. Breuza, A. Bridge, C. Casals-Casas, E. Coudert, A. Estreicher, M. Livia Famiglietti, M. Feuermann, A. Gos, N. Gruaz-Gumowski, C. Hulo, N. Hyka-Nouspikel, F. Jungo, P. Le Mercier, D. Lieberherr, P. Masson, A. Morgat, I. Pedruzzi, L. Pourcel, S. Poux, C. Rivoire, S. Sundaram, A. Bateman, E. Bowler-Barnett, H. Bye-A-Jee, P. Denny, A. Ignatchenko, R. Ishtiaq, A. Lock, Y. Lussi, M. Magrane, M. J. Martin, S. Orchard, P. Raposo, E. Speretta, N. Tyagi, K. Warner, R. Zaru, A. D. Diehl, R. Lee, J. Chan, S. Diamantakis, D. Raciti, M. Zarowiecki, M. Fisher, C. James-Zorn, V. Ponferrada, A. Zorn, S. Ramachandran, L. Ruzicka, and M. Westerfield. 2023. “The Gene Ontology knowledgebase in 2023.” Genetics 224 (1). https://doi.org/10.1093/genetics/iyad031.
Almeida, A., S. Nayfach, M. Boland, F. Strozzi, M. Beracochea, Z. J. Shi, K. S. Pollard, E. Sakharova, D. H. Parks, P. Hugenholtz, N. Segata, N. C. Kyrpides, and R. D. Finn. 2021. “A unified catalog of 204,938 reference genomes from the human gut microbiome.” Nature Biotechnology 39:105–114. https://doi.org/10.1038/s41587-020-0603-3.
Anand, N., and T. Achim. 2022. “Protein structure and sequence generation with equivariant denoising diffusion probabilistic models.” arXiv. https://doi.org/10.48550/arXiv.2205.15019.
Andersson, R., C. Gebhard, I. Miguel-Escalada, I. Hoof, J. Bornholdt, M. Boyd, Y. Chen, X. Zhao, C. Schmidl, T. Suzuki, E. Ntini, E. Arner, E. Valen, K. Li, L. Schwarzfischer, D. Glatz, J. Raithel, B. Lilje, N. Rapin, F. O. Bagger, M. Jørgensen, P. R. Andersen, N. Bertin, O. Rackham, A. M. Burroughs, J. K. Baillie, Y. Ishizu, Y. Shimizu, E. Furuhata, S. Maeda, Y. Negishi, C. J. Mungall, T. F. Meehan, T. Lassmann, M. Itoh, H. Kawaji, N. Kondo, J. Kawai, A. Lennartsson, C. O. Daub, P. Heutink, D. A. Hume, T. H. Jensen, H. Suzuki, Y. Hayashizaki, F. Müller, A. R. R. Forrest, P. Carninci, M. Rehli, and A. Sandelin. 2014. “An atlas of active enhancers across human cell types and tissues.” Nature 507:455–461. https://doi.org/10.1038/nature12787.
Avsec, Ž., V. Agarwal, D. Visentin, J. R. Ledsam, A. Grabska-Barwinska, K. R. Taylor, Y. Assael, J. Jumper, P. Kohli, and D. R. Kelley. 2021. “Effective gene expression prediction from sequence by integrating long-range interactions.” Nature Methods 18:1196–1203. https://doi.org/10.1038/s41592-021-01252-x.
Bahdanau, D., K. H. Cho, and Y. Bengio. 2014. “Neural machine translation by jointly learning to align and translate.” arXiv. https://doi.org/10.48550/arXiv.1409.0473.
Basse, M.-J., S. Betzi, X. Morelli, and P. Roche. 2016. “2P2Idb v2: Update of a structural database dedicated to orthosteric modulation of protein–protein interactions.” Database 2016:baw007. https://doi.org/10.1093/database/baw007.
Beguir, K., M. J. Skwark, Y. Fu, T. Pierrot, N. L. Carranza, A. Laterre, I. Kadri, A. Korched, A. U. Lowegard, B. G. Lui, B. Sänger, Y. Liu, A. Poran, A. Muik, and U. Şahin. 2023. “Early computational detection of potential high-risk SARS-CoV-2 variants.” Computers in Biology and Medicine 155:106618. https://doi.org/10.1016/j.compbiomed.2023.106618.
Benegas, G., C. Albors, A. J. Aw, C. Ye, and Y. S. Song. 2024. “GPN-MSA: An alignment-based DNA language model for genome-wide variant effect prediction.” bioRxiv. https://doi.org/10.1101/2023.10.10.561776.
Benegas, G., S. S. Batra, and Y. S. Song. 2023. “DNA language models are powerful predictors of genome-wide variant effects.” Proceedings of the National Academy of Sciences USA 120(44):e2311219120. https://doi.org/10.1073/pnas.2311219120.
Benjin, X., and L. Ling. 2020. “Developments, applications, and prospects of cryo-electron microscopy.” Protein Science 29(4):872–882. https://doi.org/10.1002/pro.3805.
Bennett, N. R., J. L. Watson, R. J. Ragotte, A. J. Borst, D. L. See, C. Weidle, R. Biswas, E. L. Shrock, P. J. Y. Leung, B. Huang, I. Goreshnik, R. Ault, K. D. Carr, B. Singer, C. Criswell, D. Vafeados, M. Garcia Sanchez, H. M. Kim, S. Vázquez Torres, S. Chan, and D. Baker. 2024. “Atomically accurate de novo design of single-domain antibodies.” bioRxiv. https://doi.org/10.1101/2024.03.14.585103.
Bepler, T., and B. Berger. 2021. “Learning the protein language: Evolution, structure, and function.” Cell Systems 12(6):654–669. https://doi.org/10.1016/j.cels.2021.05.017.
Berman, H. M., J. Westbrook, Z. Feng, G. Gilliland, T. N. Bhat, H. Weissig, I. N. Shindyalov, and P. E. Bourne. 2000. “The Protein Data Bank.” Nucleic Acids Research 28(1):235–242. https://doi.org/10.1093/nar/28.1.235.
Biswas, S., G. Khimulya, E. C. Alley, K. M. Esvelt, and G. M. Church. 2021. “Low-N protein engineering with data-efficient deep learning.” Nature Methods 18:389–396. https://doi.org/10.1038/s41592-021-01100-y.
Bommasani, R., D. A. Hudson, E. Adeli, R. Altman, S. Arora, S. von Arx, M. S. Bernstein, J. Bohg, A. Bosselut, E. Brunskill, E. Brynjolfsson, S. Buch, D. Card, R. Castellon, N. Chatterji, A. Chen, K. Creel, J. Q. Davis, D. Demszky, C. Donahue, M. Doumbouya, E. Durmus, S. Ermon, J. Etchemendy, K. Ethayarajh, L. Fei-Fei, C. Finn, T. Gale, L. Gillespie, K. Goel, N. Goodman, S. Grossman, N. Guha, T. Hashimoto, P. Henderson, J. Hewitt, D. E. Ho, J. Hong, K. Hsu, J. Huang, T. Icard, S. Jain, D. Jurafsky, P. Kalluri, S. Karamcheti, G. Keeling, F. Khani, O. Khattab, P. W. Koh, M. Krass, R. Krishna, R. Kuditipudi, A. Kumar, F. Ladhak, M. Lee, T. Lee, J. Leskovec, I. Levent, X. L. Li, X. Li, T. Ma, A. Malik, C. D. Manning, S. Mirchandani, E. Mitchell, Z. Munyikwa, S. Nair, A. Narayan, D. Narayanan, B. Newman, A. Nie, J. C. Niebles, H. Nilforoshan, J. Nyarko, G. Ogut, L. Orr, I. Papadimitriou, J. S. Park, C. Piech, E. Portelance, C. Potts, A. Raghunathan, R. Reich, H. Ren, F. Rong, Y. Roohani, C. Ruiz, J. Ryan, C. Ré, D. Sadigh, S. Sagawa, K. Santhanam, A. Shih, K. Srinivasan, A. Tamkin, R. Taori, A. W. Thomas, F. Tramèr, R. E. Wang, W. Wang, B. Wu, J. Wu, Y. Wu, S. M. Xie, M. Yasunaga, J. You, M. Zaharia, M. Zhang, T. Zhang, X. Zhang, Y. Zhang, L. Zheng, K. Zhou, and P. Liang. 2021. “On the opportunities and risks of foundation models.” arXiv. https://doi.org/10.48550/arXiv.2108.07258.
Brandes, N., G. Goldman, C. H. Wang, C. J. Ye, and V. Ntranos. 2023. “Genome-wide prediction of disease variant effects with a deep protein language model.” Nature Genetics 55:1512–1522. https://doi.org/10.1038/s41588-023-01465-0.
Bromberg, Y., R. Prabakaran, A. Kabir, and A. Shehu. 2024. “Variant effect prediction in the age of machine learning.” Cold Spring Harbor Perspectives in Biology 16:a041467. https://doi.org/10.1101/cshperspect.a041467.
Brown, T. B., B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amodei. 2020. “Language models are few-shot learners.” arXiv. https://doi.org/10.48550/arXiv.2005.14165.
Buenrostro, J. D., P. G. Giresi, L. C. Zaba, H. Y. Chang, and W. J. Greenleaf. 2013. “Transposition of native chromatin for fast and sensitive epigenomic profiling of open chromatin, DNA-binding proteins and nucleosome position.” Nature Methods 10:1213–1218. https://doi.org/10.1038/nmeth.2688.
Cao, Y., F. Jian, J. Wang, Y. Yu, W. Song, A. Yisimayi, J. Wang, R. An, X. Chen, N. Zhang, Y. Wang, P. Wang, L. Zhao, H. Sun, L. Yu, S. Yang, X. Niu, T. Xiao, Q. Gu, F. Shao, X. Hao, Y. Xu, R. Jin, Z. Shen, Y. Wang, and X. S. Xie. 2022. “Imprinted SARS-CoV-2 humoral immunity induces convergent Omicron RBD evolution.” Nature 614:521–529. https://doi.org/10.1038/s41586-022-05644-7.
Chang, A., L. Jeske, S. Ulbrich, J. Hofmann, J. Koblitz, I. Schomburg, M. Neumann-Schaal, D. Jahn, and D. Schomburg. 2021. “BRENDA, the ELIXIR core data resource in 2021: New developments and updates.” Nucleic Acids Research 49(D1):D498–D508. https://doi.org/10.1093/nar/gkaa1025.
Chen, J., Z. Hu, S. Sun, Q. Tan, Y. Wang, Q. Yu, L. Zong, L. Hong, J. Xiao, T. Shen, I. King, and Y. Li. 2022. “Interpretable RNA foundation model from unannotated data for highly accurate RNA structure and function predictions.” arXiv. https://doi.org/10.48550/arXiv.2204.00300.
Chu, A. E., J. Kim, L. Cheng, G. El Nesr, M. Xu, R. W. Shuai, and P.-S. Huang. 2024. “An all-atom protein generative model.” Proceedings of the National Academy of Sciences USA 121(27):e2311500121. https://doi.org/10.1073/pnas.2311500121.
Chu, A. E., T. Lu, and P.-S. Huang. 2024. “Sparks of function by de novo protein design.” Nature Biotechnology 42:203–215. https://doi.org/10.1038/s41587-024-02133-2.
Corso, G., H. Stärk, B. Jing, R. Barzilay, and T. Jaakkola. 2023. “DiffDock: Diffusion steps, twists, and turns for molecular docking.” arXiv. https://doi.org/10.48550/arXiv.2210.01776.
Courbet, A., J. Hansen, Y. Hsia, N. Bethel, Y.-J. Park, C. Xu, A. Moyer, S. E. Boyken, G. Ueda, U. Nattermann, D. Nagarajan, D.-A. Silva, W. Sheffler, J. Quispe, A. Nord, N. King, P. Bradley, D. Veesler, J. Kollman, and D. Baker. 2022. “Computational design of mechanically coupled axle-rotor protein assemblies.” Science 376(6591):383–390. https://doi.org/10.1126/science.abm1183.
Cui, H., C. Wang, H. Maan, K. Pang, F. Luo, N. Duan, and B. Wang. 2024. “scGPT: Toward building a foundation model for single-cell multi-omics using generative AI.” Nature Methods 21:1470–1480. https://doi.org/10.1038/s41592-024-02201-0.
CZI Single-Cell Biology Program, S. Abdulla, B. Aevermann, P. Assis, S. Badajoz, S. M. Bell, E. Bezzi, B. Cakir, J. Chaffer, S. Chambers, J. Michael Cherry, T. Chi, J. Chien, L. Dorman, P. Garcia-Nieto, N. Gloria, M. Hastie, D. Hegeman, J. Hilton, T. Huang, A. Infeld, A.-M. Istrate, I. Jelic, K. Katsuya, Y. J. Kim, K. Liang, M. Lin, M. Lombardo, B. Marshall, B. Martin, F. McDade, C. Megill, N. Patel, A. Predeus, B. Raymor, B. Robatmili, D. Rogers, E. Rutherford, D. Sadgat, A. Shin, C. Small, T. Smith, P. Sridharan, A. Tarashansky, N. Tavares, H. Thomas, A. Tolopko, M. Urisko, J. Yan, G. Yeretssian, J. Zamanian, A. Mani, J. Cool, and A. Carr. 2023. “CZ CELLxGENE Discover: A single-cell data platform for scalable exploration, analysis and modeling of aggregated data.” bioRxiv. https://doi.org/10.1101/2023.10.30.563174.
Dallago, C., J. Mou, K. E. Johnston, B. J. Wittmann, N. Bhattacharya, S. Goldman, A. Madani, and K. K. Yang. 2021. “FLIP: Benchmark tasks in fitness landscape inference for proteins.” bioRxiv. https://doi.org/10.1101/2021.11.09.467890.
Dalla-Torre, H., L. Gonzalez, J. Mendoza-Revilla, N. L. Carranza, A. H. Grzywaczewski, F. Oteri, C. Dallago, E. Trop, B. P. de Almeida, H. Sirelkhatim, G. Richard, M. Skwark, K. Beguir, M. Lopez, and T. Pierrot. 2023. “The Nucleotide Transformer: Building and evaluating robust foundation models for human genomics.” bioRxiv. https://doi.org/10.1101/2023.01.11.523679.
DaSilva, L. F., S. Senan, Z. M. Patel, A. J. Reddy, S. Gabbita, Z. Nussbaum, C. M. V. Córdova, A. Wenteler, N. Weber, T. M. Tunjic, T. A. Khan, Z. Li, C. Smith, M. Bejan, L. K. Louis, P. Cornejo, W. Connell, E. S. Wong, W. Meuleman, and L. Pinello. 2024. “DNA-diffusion: Leveraging generative models for controlling chromatin accessibility and gene expression via synthetic regulatory elements.” bioRxiv. https://doi.org/10.1101/2024.02.01.578352.
Dauparas, J., I. Anishchenko, N. Bennett, H. Bai, R. J. Ragotte, L. F. Milles, B. I. M. Wicky, A. Courbet, R. J. de Haas, N. Bethel, P. J. Y. Leung, T. F. Huddy, S. Pellock, D. Tischer, F. Chan, B. Koepnick, H. Nguyen, A. Kang, B. Sankaran, A. K. Bera, N. P. King, and D. Baker. 2022. “Robust deep learning–based protein sequence design using ProteinMPNN.” Science 378(6615):49–56. https://doi.org/10.1126/science.add2187.
Dekker, J., A. S. Belmont, M. Guttman, V. O. Leshyk, J. T. Lis, S. Lomvardas, L. A. Mirny, C. C. O’Shea, P. J. Park, B. Ren, J. C. R. Politz, J. Shendure, and S. Zhong. 2017. “The 4D nucleome project.” Nature 549:219–226. https://doi.org/10.1038/nature23884.
Devlin, J., M.-W. Chang, K. Lee, and K. Toutanova. 2018. “BERT: Pre-training of deep bidirectional transformers for language understanding.” arXiv. https://doi.org/10.48550/arXiv.1810.04805.
El-Gebali, S., J. Mistry, A. Bateman, S. R. Eddy, A. Luciani, S. C. Potter, M. Qureshi, L. J. Richardson, G. A. Salazar, A. Smart, E. L. L. Sonnhammer, L. Hirsh, L. Paladin, D. Piovesan, S. C. E. Tosatto, and R. D. Finn. 2019. “The Pfam protein families database in 2019.” Nucleic Acids Research 47 (D1):D427–D432. https://doi.org/10.1093/nar/gky995.
Elnaggar, A., M. Heinzinger, C. Dallago, G. Rehawi, Y. Wang, L. Jones, T. Gibbs, T. Feher, C. Angerer, M. Steinegger, D. Bhowmik, and B. Rost. 2022. “ProtTrans: Towards understanding the language of life through self-supervised learning.” IEEE Transactions on Pattern Analysis and Machine Intelligence 44(10):7112–7127. https://doi.org/10.1109/TPAMI.2021.3095381.
ENCODE Project Consortium. 2012. “An integrated encyclopedia of DNA elements in the human genome.” Nature 489:57–74. https://doi.org/10.1038/nature11247.
Ferruz, N., S. Schmidt, and B. Höcker. 2022. “ProtGPT2 is a deep unsupervised language model for protein design.” Nature Communications 13(4348). https://doi.org/10.1038/s41467-022-32007-7.
Foley, B., T. Leitner, C. Apetrei, B. Hahn, I. Mizrachi, J. Mullins, A. Rambaut, S. Wolinsky, and B. Korber, eds. 2018. HIV Sequence Compendium 2018. Los Alamos, NM: Los Alamos National Laboratory. https://doi.org/10.2172/1458915.
Forster, S. C., N. Kumar, B. O. Anonye, A. Almeida, E. Viciani, M. D. Stares, M. Dunn, T. T. Mkandawire, A. Zhu, Y. Shao, L. J. Pike, T. Louie, H. P. Browne, A. L. Mitchell, B. A. Neville, R. D. Finn, and T. D. Lawley. 2019. “A human gut bacterial genome and culture collection for improved metagenomic analyses.” Nature Biotechnology 37:186–192. https://doi.org/10.1038/s41587-018-0009-7.
Fowler, D. M., C. L. Araya, S. J. Fleishman, E. H. Kellogg, J. J. Stephany, D. Baker, and S. Fields. 2010. “High-resolution mapping of protein sequence-function relationships.” Nature Methods 7:741–746. https://doi.org/10.1038/nmeth.1492.
Fowler, D. M., and S. Fields. 2014. “Deep mutational scanning: A new style of protein science.” Nature Methods 11:801–807. https://doi.org/10.1038/nmeth.3027.
Giani, A. M., G. R. Gallo, L. Gianfranceschi, and G. Formenti. 2020. “Long walk to genomics: History and current approaches to genome sequencing and assembly.” Computational and Structural Biotechnology Journal 18:9–19. https://doi.org/10.1016/j.csbj.2019.11.002.
Goodfellow, I., Y. Bengio, and A. Courville. 2016. Deep Learning. Cambridge: MIT Press.
Greenberg, M. V. C., and D. Bourc’his. 2019. “The diverse roles of DNA methylation in mammalian development and disease.” Nature Reviews Molecular Cell Biology 20:590–607. https://doi.org/10.1038/s41580-019-0159-6.
Greenhalgh, J. C., S. A. Fahlberg, B. F. Pfleger, and P. A. Romero. 2021. “Machine learning-guided acyl-ACP reductase engineering for improved in vivo fatty alcohol production.” Nature Communications 12:5825. https://doi.org/10.1038/s41467-021-25831-w.
Gu, A., and T. Dao. 2023. “Mamba: Linear-time sequence modeling with selective state spaces.” arXiv. https://doi.org/10.48550/arXiv.2312.00752.
Haddox, H. K., A. S. Dingens, and J. D. Bloom. 2016. “Experimental estimation of the effects of all amino-acid mutations to HIV’s envelope protein on viral replication in cell culture.” PLOS Pathogens 12:e1006114. https://doi.org/10.1371/journal.ppat.1006114.
Haddox, H. K., A. S. Dingens, S. K. Hilton, J. Overbaugh, and J. D. Bloom. 2018. “Mapping mutational effects along the evolutionary landscape of HIV envelope.” eLife 7:e34420. https://doi.org/10.7554/eLife.34420.
Hao, M., J. Gong, X. Zeng, C. Liu, Y. Guo, X. Cheng, T. Wang, J. Ma, X. Zhang, and L. Song. 2024. “Large-scale foundation model on single-cell transcriptomics.” Nature Methods 21:1481–1491. https://doi.org/10.1038/s41592-024-02305-7.
Hastie, T., R. Tibshirani, and J. H. Friedman. 2009. The Elements of Statistical Learning: Data Mining, Inference, and Prediction. Vol. 2. New York: Springer.
Hayes, T., R. Rao, H. Akin, N. J. Sofroniew, D. Oktay, Z. Lin, R. Verkuil, V. Q. Tran, J. Deaton, M. Wiggert, R. Badkundri, I. Shafkat, J. Gong, A. Derry, R. S. Molina, N. Thomas, Y. Khan, C. Mishra, C. Kim, L. J. Bartie, M. Nemeth, P. D. Hsu, T. Sercu, S. Candido, and A. Rives. 2024. “Simulating 500 million years of evolution with a language model.” bioRxiv. https://doi.org/10.1101/2024.07.01.600583.
Hesslow, D., N. Zanichelli, P. Notin, I. Poli, and D. Marks. 2022. “RITA: A study on scaling up generative protein sequence models.” arXiv. https://doi.org/10.48550/arXiv.2205.05789.
Hie, B., E. Zhong, B. Berger, and B. Bryson. 2021. “Learning the language of viral evolution and escape.” Science 371(6526):284–288. https://doi.org/10.1126/science.abd7331.
Hie, B. L., B. D. Bryson, and B. Berger. 2020. “Leveraging uncertainty in machine learning accelerates biological discovery and design.” Cell Systems 11:461–477. https://doi.org/10.1016/j.cels.2020.09.007.
Hie, B. L., and K. K. Yang. 2022. “Adaptive machine learning for protein engineering.” Current Opinion in Structural Biology 72:145–152. https://doi.org/10.1016/j.sbi.2021.11.002.
Hie, B. L., K. K. Yang, and P. S. Kim. 2022. “Evolutionary velocity with protein language models predicts evolutionary dynamics of diverse proteins.” Cell Systems 13 (4):274–285. https://doi.org/10.1016/j.cels.2022.01.003.
Hie, B. L., V. R. Shanker, D. Xu, T. U. J. Bruun, P. A. Weidenbacher, S. Tang, W. Wu, J. E. Pak, and P. S. Kim. 2024. “Efficient evolution of human antibodies from general protein language models.” Nature Biotechnology 42:275–283. https://doi.org/10.1038/s41587-023-01763-2.
Ho, J., A. Jain, and P. Abbeel. 2020. “Denoising diffusion probabilistic models.” arXiv. https://doi.org/10.48550/arXiv.2006.11239.
Hoffmann, J., S. Borgeaud, A. Mensch, E. Buchatskaya, T. Cai, E. Rutherford, D. de Las Casas, L. A. Hendricks, J. Welbl, A. Clark, T. Hennigan, E. Noland, K. Millican, G. van den Driessche, B. Damoc, A. Guy, S. Osindero, K. Simonyan, E. Elsen, J. W. Rae, O. Vinyals, and L. Sifre. 2022. “Training compute-optimal large language models.” arXiv. https://doi.org/10.48550/arXiv.2203.15556.
Hsu, C., H. Nisonoff, C. Fannjiang, and J. Listgarten. 2022. “Learning protein fitness models from evolutionary and assay-labeled data.” Nature Biotechnology 40:1114–1122. https://doi.org/10.1038/s41587-021-01146-5.
Hsu, C., R. Verkuil, J. Liu, Z. Lin, B. Hie, T. Sercu, A. Lerer, and A. Rives. 2022. “Learning inverse folding from millions of predicted structures.” Proceedings of the 39th International Conference on Machine Learning 162:8946–8970. https://proceedings.mlr.press/v162/hsu22a.html.
Huang, L., T. Xu, Y. Yu, P. Zhao, X. Chen, J. Han, Z. Xie, H. Li, W. Zhong, K.-C. Wong, and H. Zhang. 2024. “A dual diffusion model enables 3D molecule generation and lead optimization based on target pockets.” Nature Communications 15:2657. https://doi.org/10.1038/s41467-024-46569-1.
Hunter, S. A., and J. R. Cochran. 2016. “Cell-binding assays for determining the affinity of protein–protein interactions.” Methods Enzymology 580:21–44. https://doi.org/10.1016/bs.mie.2016.05.002.
Ingraham, J. B., M. Baranov, Z. Costello, K. W. Barber, W. Wang, A. Ismail, V. Frappier, D. M. Lord, C. Ng-Thow-Hing, E. R. Van Vlack, S. Tie, V. Xue, S. C. Cowles, A. Leung, J. V. Rodrigues, C. L. Morales-Perez, A. M. Ayoub, R. Green, K. Puentes, F. Oplinger, N. V. Panwar, F. Obermeyer, A. R. Root, A. L. Beam, F. J. Poelwijk, and G. Grigoryan. 2023. “Illuminating protein space with a programmable generative model.” Nature 623:1070–1078. https://doi.org/10.1038/s41586-023-06728-8.
Ito, J., A. Strange, W. Liu, G. Joas, S. Lytras, and K. Sato. 2024. “A protein language model for exploring viral fitness landscapes.” bioRxiv. https://doi.org/10.1101/2024.03.15.584819.
Jacquier, H., A. Birgy, H. Le Nagard, Y. Mechulam, E. Schmitt, J. Glodt, B. Bercot, E. Petit, J. Poulain, G. Barnaud, P.-A. Gros, and O. Tenaillon. 2013. “Capturing the mutational landscape of the beta-lactamase TEM-1.” Proceedings of the National Academy of Sciences USA 110(32):13067–13072. https://doi.org/10.1073/pnas.1215206110.
Jankauskaitė, J., B. Jiménez-García, J. Dapkūnas, J. Fernández-Recio, and I. H. Moal. 2019. “SKEMPI 2.0: An updated benchmark of changes in protein–protein binding energy, kinetics and thermodynamics upon mutation.” Bioinformatics 35(3):462–469. https://doi.org/10.1093/bioinformatics/bty635.
Jones, R. C., J. Karkanias, M. A. Krasnow, A. O. Pisco, S. R. Quake, J. Salzman, N. Yosef, B. Bulthaup, P. Brown, W. Harper, M. Hemenez, R. Ponnusamy, A. Salehi, B. A. Sanagavarapu, E. Spallino, K. A. Aaron, W. Concepcion, J. M. Gardner, B. Kelly, N. Neidlinger, Z. Wang, S. Crasta, S. Kolluru, M. Morri, A. O. Pisco, S. Y. Tan, K. J. Travaglini, C. Xu, M. Alcántara-Hernández, N. Almanzar, J. Antony, B. Beyersdorf, D. Burhan, K. Calcuttawala, M. M. Carter, C. K. F. Chan, C. A. Chang, S. Chang, A. Colville, S. Crasta, R. N. Culver, I. Cvijović, G. D’Amato, C. Ezran, F. X. Galdos, A. Gillich, W. R. Goodyer, Y. Hang, A. Hayashi, S. Houshdaran, X. Huang, J. C. Irwin, S. Jang, J. V. Juanico, A. M. Kershner, S. Kim, B. Kiss, S. Kolluru, W. Kong, M. E. Kumar, A. H. Kuo, R. Leylek, B. Li, G. B. Loeb, W.-J. Lu, S. Mantri, M. Markovic, P. L. McAlpine, A. de Morree, M. Morri, K. Mrouj, S. Mukherjee, T. Muser, P. Neuhöfer, T. D. Nguyen, K. Perez, R. Phansalkar, A. O. Pisco, N. Puluca, Z. Qi, P. Rao, H. Raquer-McKay, N. Schaum, B. Scott, B. Seddighzadeh, J. Segal, S. Sen, S. Sikandar, S. P. Spencer, L. C. Steffes, V. R. Subramaniam, A. Swarup, M. Swift, K. J. Travaglini, W. Van Treuren, E. Trimm, S. Veizades, S. Vijayakumar, K. C. Vo, S. K. Vorperian, W. Wang, H. N. W. Weinstein, J. Winkler, T. T. H. Wu, J. Xie, A. R. Yung, Y. Zhang, A. M. Detweiler, H. Mekonen, N. F. Neff, R. V. Sit, M. Tan, J. Yan, G. R. Bean, V. Charu, E. Forgó, B. A. Martin, M. G. Ozawa, O. Silva, S. Y. Tan, A. Toland, V. N. P. Vemuri, S. Afik, K. Awayan, O. B. Botvinnik, A. Byrne, M. Chen, R. Dehghannasiri, A. M. Detweiler, A. Gayoso, A. A. Granados, Q. Li, G. Mahmoudabadi, A. McGeever, A. de Morree, J. E. Olivieri, M. Park, A. O. Pisco, N. Ravikumar, J. Salzman, G. Stanley, M. Swift, M. Tan, W. Tan, A. J. Tarashansky, R. Vanheusden, S. K. Vorperian, P. Wang, S. Wang, G. Xing, C. Xu, N. Yosef, M. Alcántara-Hernández, J. Antony, C. K. F. Chan, C. A. Chang, A. Colville, S. Crasta, R. Culver, L. Dethlefsen, C. Ezran, A. Gillich, Y. Hang, P.-Y. Ho, J. C. Irwin, S. Jang, A. M. Kershner, W. Kong, M. E. Kumar, A. H. Kuo, R. Leylek, S. Liu, G. B. Loeb, W.-J. Lu, J. S. Maltzman, R. J. Metzger, A. de Morree, P. Neuhöfer, K. Perez, R. Phansalkar, Z. Qi, P. Rao, H. Raquer-McKay, K. Sasagawa, B. Scott, R. Sinha, H. Song, S. P. Spencer, A. Swarup, M. Swift, K. J. Travaglini, E. Trimm, S. Veizades, S. Vijayakumar, B. Wang, W. Wang, J. Winkler, J. Xie, A. R. Yung, S. E. Artandi, P. A. Beachy, M. F. Clarke, L. C. Giudice, F. W. Huang, K. C. Huang, J. Idoyaga, S. K. Kim, M. Krasnow, C. S. Kuo, P. Nguyen, S. R. Quake, T. A. Rando, K. Red-Horse, J. Reiter, D. A. Relman, J. L. Sonnenburg, B. Wang, A. Wu, S. M. Wu, and T. Wyss-Coray. 2022. “The Tabula Sapiens: A multiple-organ, single-cell transcriptomic atlas of humans.” Science 376:eabl4896. https://doi.org/10.1126/science.abl4896.
Jumper, J., R. Evans, A. Pritzel, T. Green, M. Figurnov, O. Ronneberger, K. Tunyasuvunakool, R. Bates, A. Žídek, A. Potapenko, A. Bridgland, C. Meyer, S. A. A. Kohl, A. J. Ballard, A. Cowie, B. Romera-Paredes, S. Nikolov, R. Jain, J. Adler, T. Back, S. Petersen, D. Reiman, E. Clancy, M. Zielinski, M. Steinegger, M. Pacholska, T. Berghammer, S. Bodenstein, D. Silver, O. Vinyals, A. W. Senior, K. Kavukcuoglu, P. Kohli, and D. Hassabis. 2021. “Highly accurate protein structure prediction with AlphaFold.” Nature 596:583–589. https://doi.org/10.1038/s41586-021-03819-2.
Kabir, A., A. Moldwin, Y. Bromberg, and A. Shehu. 2024. “In the twilight zone of protein sequence homology: Do protein language models learn protein structure?” Bioinformatics Advances 4(1). https://doi.org/10.1093/bioadv/vbae119.
Kalvari, I., E. P. Nawrocki, N. Ontiveros-Palacios, J. Argasinska, K. Lamkiewicz, M. Marz, S. Griffiths-Jones, C. Toffano-Nioche, D. Gautheret, Z. Weinberg, E. Rivas, S. R. Eddy, R. D. Finn, A. Bateman, and A. I. Petrov. 2021. “Rfam 14: Expanded coverage of metagenomic, viral and microRNA families.” Nucleic Acids Research 49(D1):D192–D200. https://doi.org/10.1093/nar/gkaa1047.
Kaplan, J., S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei. 2020. “Scaling laws for neural language models.” arXiv. https://doi.org/10.48550/arXiv.2001.08361.
Kedzierska, K. Z., L. Crawford, A. P. Amini, and A. X. Lu. 2023. “Assessing the limits of zero-shot foundation models in single-cell biology.” bioRxiv. https://doi.org/10.1101/2023.10.16.561085.
Kenlay, H., F. A. Dreyer, A. Kovaltsuk, D. Miketa, D. Pires, and C. M. Deane. 2024. “Large scale paired antibody language models.” arXiv. https://doi.org/10.48550/arXiv.2403.17889.
Kingma, D. P., and M. Welling. 2014. “Auto-encoding variational Bayes.” arXiv. https://doi.org/10.48550/arXiv.1312.6114.
Knox, C., V. Law, T. Jewison, P. Liu, S. Ly, A. Frolkis, A. Pon, K. Banco, C. Mak, V. Neveu, Y. Djoumbou, R. Eisner, A. C. Guo, and D. S. Wishart. 2011. “DrugBank 3.0: A comprehensive resource for ‘Omics’ research on drugs.” Nucleic Acids Research 39:D1035–D1041. https://doi.org/10.1093/nar/gkq1126.
Knudsen, M., and C. Wiuf. 2010. “The CATH database.” Human Genomics 4:207. https://doi.org/10.1186/1479-7364-4-3-207.
Krishna, R., J. Wang, W. Ahern, P. Sturmfels, P. Venkatesh, I. Kalvet, G. R. Lee, F. S. MoreyBurrows, I. Anishchenko, I. R. Humphreys, R. McHugh, D. Vafeados, X. Li, G. A. Sutherland, A. Hitchcock, C. N. Hunter, A. Kang, E. Brackenbrough, A. K. Bera, M. Baek, F. DiMaio, and D. Baker. 2024. “Generalized biomolecular modeling and design with RoseTTAFold All-Atom.” Science 384(6693). https://doi.org/10.1126/science.adl2528.
Kundaje, A., W. Meuleman, J. Ernst, M. Bilenky, A. Yen, A. Heravi-Moussavi, P. Kheradpour, Z. Zhang, J. Wang, M. J. Ziller, V. Amin, J. W. Whitaker, M. D. Schultz, L. D. Ward, A. Sarkar, G. Quon, R. S. Sandstrom, M. L. Eaton, Y.-C. Wu, A. R. Pfenning, X. Wang, M. Claussnitzer, Y. Liu, C. Coarfa, R. A. Harris, N. Shoresh, C. B. Epstein, E. Gjoneska, D. Leung, W. Xie, R. D. Hawkins, R. Lister, C. Hong, P. Gascard, A. J. Mungall, R. Moore, E. Chuah, A. Tam, T. K. Canfield, R. S. Hansen, R. Kaul, P. J. Sabo, M. S. Bansal, A. Carles, J. R. Dixon, K.-H. Farh, S. Feizi, R. Karlic, A.-R. Kim, A. Kulkarni, D. Li, R. Lowdon, G. Elliott, T. R. Mercer, S. J. Neph, V. Onuchic, P. Polak, N. Rajagopal, P. Ray, R. C. Sallari, K. T. Siebenthall, N. A. Sinnott-Armstrong, M. Stevens, R. E. Thurman, J. Wu, B. Zhang, X. Zhou, A. E. Beaudet, L. A. Boyer, P. L. De Jager, P. J. Farnham, S. J. Fisher, D. Haussler, S. J. M. Jones, W. Li, M. A. Marra, M. T. McManus, S. Sunyaev, J. A. Thomson, T. D. Tlsty, L.-H. Tsai, W. Wang, R. A. Waterland, M. Q. Zhang, L. H. Chadwick, B. E. Bernstein, J. F. Costello, J. R. Ecker, M. Hirst, A. Meissner, A. Milosavljevic, B. Ren, J. A. Stamatoyannopoulos, T. Wang, and M. Kellis. 2015. “Integrative analysis of 111 reference human epigenomes.” Nature 518:317–330. https://doi.org/10.1038/nature14248.
LaFleur, T. L., A. Hossain, and H. M. Salis. 2022. “Automated model-predictive design of synthetic promoters to control transcriptional profiles in bacteria.” Nature Communications 13:5159. https://doi.org/10.1038/s41467-022-32829-5.
Lal, A., D. Garfield, T. Biancalani, and G. Eraslan. 2024. “regLM: Designing realistic regulatory DNA with autoregressive language models.” bioRxiv. https://doi.org/10.1101/2024.02.14.580373.
Lamb, K. D., J. Hughes, S. Lytras, O. Koci, F. Young, J. Grove, K. Yuan, and D. L. Robertson. 2024. “From a single sequence to evolutionary trajectories: Protein language models capture the evolutionary potential of SARS-CoV-2 protein sequences.” bioRxiv. https://doi.org/10.1101/2024.07.05.602129.
Landrum, M. J., J. M. Lee, M. Benson, G. R. Brown, C. Chao, S. Chitipiralla, B. Gu, J. Hart, D. Hoffman, W. Jang, K. Karapetyan, K. Katz, C. Liu, Z. Maddipatla, A. Malheiro, K. McDaniel, M. Ovetsky, G. Riley, G. Zhou, J B. Holmes, B. L. Kattman, and D. R. Maglott. 2018. “ClinVar: Improving access to variant interpretations and supporting evidence.” Nucleic Acids Research 46(D1):D1062–D1067. https://doi.org/10.1093/nar/gkx1153.
LeCun, Y., B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, and L. D. Jackel. 1989. “Backpropagation applied to handwritten zip code recognition.” Neural Computation 1 (4):541–551. https://doi.org/10.1162/neco.1989.1.4.541.
Lee, J. M., J. Huddleston, M. B. Doud, K. A. Hooper, N. C. Wu, T. Bedford, and J. D. Bloom. 2018. “Deep mutational scanning of hemagglutinin helps predict evolutionary fates of human H3N2 influenza variants.” Proceedings of the National Academy of Sciences USA 115(35):E8276–E8285. https://doi.org/10.1073/pnas.1806133115.
Leem, J., L. S. Mitchell, J. H. R. Farmery, J. Barton, and J. D. Galson. 2022. “Deciphering the language of antibodies using self-supervised learning.” Patterns 3(7):100513. https://doi.org/10.1016/j.patter.2022.100513.
Li, H., J. Janssens, M. De Waegeneer, S. S. Kolluru, K. Davie, V. Gardeux, W. Saelens, F. P. A. David, M. Brbić, K. Spanier, J. Leskovec, C. N. McLaughlin, Q. Xie, R. C. Jones, K. Brueckner, J. Shim, S. G. Tattikota, F. Schnorrer, K. Rust, T. G. Nystul, Z. CarvalhoSantos, C. Ribeiro, S. Pal, S. Mahadevaraju, T. M. Przytycka, A. M. Allen, S. F. Goodwin, C. W. Berry, M. T. Fuller, H. White-Cooper, E. L. Matunis, S. DiNardo, A. Galenza, L. E. O’Brien, J. A. T. Dow, H. Jasper, B. Oliver, N. Perrimon, B. Deplancke, S. R. Quake, L. Luo, S. Aerts, D. Agarwal, Y. Ahmed-Braimah, M. Arbeitman, M. M. Ariss, J. Augsburger, K. Ayush, C. C. Baker, T. Banisch, K. Birker, R. Bodmer, B. Bolival, S. E. Brantley, J. A. Brill, N. C. Brown, N. A. Buehner, X. T. Cai, R. Cardoso-Figueiredo, F. Casares, A. Chang, T. R. Clandinin, S. Crasta, C. Desplan, A. M. Detweiler, D. B. Dhakan, E. Donà, S. Engert, S. Floc’hlay, N. George, A. J. González-Segarra, A. K. Groves, S. Gumbin, Y. Guo, D. E. Harris, Y. Heifetz, S. L. Holtz, F. Horns, B. Hudry, R.-J. Hung, Y. N. Jan, J. S. Jaszczak, G. S. X. E. Jefferis, J. Karkanias, T. L. Karr, N. S. Katheder, J. Kezos, A. A. Kim, S. K. Kim, L. Kockel, N. Konstantinides, T. B. Kornberg, H. M. Krause, A. T. Labott, M. Laturney, R. Lehmann, S. Leinwand, , J. Li, J. S. S. Li, K. Li, K. Li, L. Li, T. Li, M. Litovchenko, H.-H. Liu, Y. Liu, T.-C. Lu, J. Manning, A. Mase, M. Matera-Vatnick, N. R. Matias, C. E. McDonough-Goldstein, A. McGeever, A. D. McLachlan, P. Moreno-Roman, N. Neff, M. Neville, S. Ngo, T. Nielsen, C. E. O’Brien, D. Osumi-Sutherland, M. N. Özel, I. Papatheodorou, M. Petkovic, C. Pilgrim, A. O. Pisco, C. Reisenman, E. N. Sanders, G. dos Santos, K. Scott, A. Sherlekar, P. Shiu, D. Sims, R. V. Sit, M. Slaidina, H. E. Smith, G. Sterne, Y.-H. Su, D. Sutton, M. Tamayo, M. Tan, I. Tastekin, C. Treiber, D. Vacek, G. Vogler, S. Waddell, W. Wang, R. I. Wilson, M. F. Wolfner, Y.-C. E. Wong, A. Xie, J. Xu, S. Yamamoto, J. Yan, Z. Yao, K. Yoda, R. Zhu, and R. P. Zinzen. 2022. “Fly Cell Atlas: A single-nucleus transcriptomic atlas of the adult fruit fly.” Science 375(6584). https://doi.org/10.1126/science.abk2432.
Lieberman-Aiden, E., N. L. van Berkum, L. Williams, M. Imakaev, T. Ragoczy, A. Telling, I. Amit, B. R. Lajoie, P. J. Sabo, M. O. Dorschner, R. Sandstrom, B. Bernstein, M. A. Bender, M. Groudine, A. Gnirke, J. Stamatoyannopoulos, L. A. Mirny, E. S. Lander, and J. Dekker. 2009. “Comprehensive mapping of long-range interactions reveals folding principles of the human genome.” Science 326(5950):289–293. https://doi.org/10.1126/science.1181369.
Lin, Z., H. Akin, R. Rao, B. Hie, Z. Zhu, W. Lu, N. Smetanin, R. Verkuil, O. Kabeli, Y. Shmueli, A. dos Santos Costa, M. Fazel-Zarandi, T. Sercu, S. Candido, and A. Rives. 2023. “Evolutionary-scale prediction of atomic-level protein structure with a language model.” Science 379(6637):1123–1130. https://doi.org/10.1126/science.ade2574.
Lin, Z., T. Sercu, Y. LeCun, and A. Rives. 2021. “Deep generative models create new and diverse protein structures.” Machine Learning for Structural Biology Workshop, December 13. https://neurips.cc/virtual/2021/workshop/21869.
Linder, J., D. Srivastava, H. Yuan, V. Agarwal, and D. R. Kelley. 2023. “Predicting RNA-seq coverage from DNA sequence as a unifying model of gene regulation.” bioRxiv. https://doi.org/10.1101/2023.08.30.555582.
Liu, T., Y. Lin, X. Wen, R. N. Jorissen, and M. K. Gilson. 2007. “BindingDB: A web-accessible database of experimentally determined protein-ligand binding affinities.” Nucleic Acids Research 35:D198–D201. https://doi.org/10.1093/nar/gkl999.
Livesey, B. J., and J. A. Marsh. 2020. “Using deep mutational scanning to benchmark variant effect predictors and identify disease mutations.” Molecular Systems Biology 16:e9380. https://doi.org/10.15252/msb.20199380.
Livesey, B. J., and J. A. Marsh. 2023. “Updated benchmarking of variant effect predictors using deep mutational scanning.” Molecular Systems Biology 19:e11474. https://doi.org/10.15252/msb.202211474.
Lou, A., C. Meng, and S. Ermon. 2023. “Discrete diffusion modeling by estimating the ratios of the data distribution.” arXiv. https://doi.org/10.48550/arXiv.2310.16834.
Madani, A., B. Krause, E. R. Greene, S. Subramanian, B. P. Mohr, J. M. Holton, J. L. Olmos, C. Xiong, Z. Z. Sun, R. Socher, J. S. Fraser, and N. Naik. 2023. “Large language models generate functional protein sequences across diverse families.” Nature Biotechnology 41:1099–1106. https://doi.org/10.1038/s41587-022-01618-2.
Madani, A., B. McCann, N. Naik, N. S. Keskar, N. Anand, R. R. Eguchi, P.-S. Huang, and R. Socher. 2021. “ProGen: Language modeling for protein generation.” bioRxiv. https://doi.org/10.1101/2020.03.07.982272.
Markin, C. J., D. A. Mokhtari, F. Sunden, M. J. Appel, E. Akiva, S. A. Longwell, C. Sabatti, D. Herschlag, and P. M. Fordyce. 2021. “Revealing enzyme functional architecture via high-throughput microfluidic enzyme kinetics.” Science 373 (6553). https://doi.org/10.1126/science.abf8761.
Markowitz, V. M., F. Korzeniewski, K. Palaniappan, E. Szeto, G. Werner, A. Padki, X. Zhao, I. Dubchak, P. Hugenholtz, I. Anderson, A. Lykidis, K. Mavromatis, N. Ivanova, and N. C. Kyrpides. 2006. “The integrated microbial genomes (IMG) system.” Nucleic Acids Research 34:D344–D348. https://doi.org/10.1093/nar/gkj024.
Martin, F. J., M. R. Amode, A. Aneja, O. Austine-Orimoloye, A. G. Azov, I. Barnes, A. Becker, R. Bennett, A. Berry, J. Bhai, S. K. Bhurji, A. Bignell, S. Boddu, P. R. Branco Lins, L. Brooks, S. B. Ramaraju, M. Charkhchi, A. Cockburn, L. Da Rin Fiorretto, C. Davidson, K. Dodiya, S. Donaldson, B. El Houdaigui, T. El Naboulsi, R. Fatima, C. G. Giron, T. Genez, G. S. Ghattaoraya, J. G. Martinez, C. Guijarro, M. Hardy, Z. Hollis, T. Hourlier, T. Hunt, M. Kay, V. Kaykala, T. Le, D. Lemos, D. Marques-Coelho, J. C. Marugán, G. A. Merino, L. P. Mirabueno, A. Mushtaq, S. N. Hossain, D. N. Ogeh, M. P. Sakthivel, A. Parker, M. Perry, I. Piližota, I. Prosovetskaia, J. G. Pérez-Silva, A. I. A. Salam, N. Saraiva-Agostinho, H. Schuilenburg, D. Sheppard, S. Sinha, B. Sipos, W. Stark, E. Steed, R. Sukumaran, D. Sumathipala, M.-M. Suner, L. Surapaneni, K. Sutinen, M. Szpak, F. F. Tricomi, D. Urbina-Gómez, A. Veidenberg, T. A. Walsh, B. Walts, E. Wass, N. Willhoft, J. Allen, J. Alvarez-Jarreta, M. Chakiachvili, B. Flint, S. Giorgetti, L. Haggerty, G. R. Ilsley, J. E. Loveland, B. Moore, J. M. Mudge, J. Tate, D. Thybert, S. J. Trevanion, A. Winterbottom, A. Frankish, S. E. Hunt, M. Ruffier, F. Cunningham, S. Dyer, R. D. Finn, K. L. Howe, P. W. Harrison, A. D. Yates, and P. Flicek. 2023. “Ensembl 2023.” Nucleic Acids Research 51(D1):D933-D941. https://doi.org/10.1093/nar/gkac958.
Meier, J., R. Rao, R. Verkuil, J. Liu, T. Sercu, and A. Rives. 2021. “Language models enable zero-shot prediction of the effects of mutations on protein function.” Advances in Neural Information Processing Systems 34:29287–29303. Red Hook, NY: Curran Associates, Inc.
Nguyen, E., M. Poli, M. G. Durrant, A. W. Thomas, B. Kang, J. Sullivan, M. Y. Ng, A. Lewis, A. Patel, A. Lou, S. Ermon, S. A. Baccus, T. Hernandez-Boussard, C. Ré, P. D. Hsu, and B. L. Hie. 2024. “Sequence modeling and design from molecular to genome scale with Evo.” bioRxiv. https://doi.org/10.1101/2024.02.27.582234.
Nguyen, E., M. Poli, M. Faizi, A. Thomas, M. Wornow, C. Birch-Sykes, S. Massaroli, A. Patel, C. Rabideau, Y. Bengio, S. Ermon, S. A. Baccus, and C. Ré. 2023. “HyenaDNA: Long-range genomic sequence modeling at single nucleotide resolution” Proceedings of the 37th International Conference on Neural Information Processing Systems 43177–43201. Red Hook, NY: Curran Associates, Inc.
Nijkamp, E., J. A. Ruffolo, E. N. Weinstein, N. Naik, and A. Madani. 2023. “ProGen2: Exploring the boundaries of protein language models.” Cell Systems 14(11):968–978. e3. https://doi.org/10.1016/j.cels.2023.10.002.
Nikam, R., A. Kulandaisamy, K. Harini, D. Sharma, and M. M. Gromiha. 2021. “ProThermDB: Thermodynamic database for proteins and mutants revisited after 15 years.” Nucleic Acids Research 49(D1):D420–D424. https://doi.org/10.1093/nar/gkaa1035.
Notin, P., A. Kollasch, D. Ritter, L. Van Niekerk, S. Paul, H. Spinner, N. Rollins, A. Shaw, R. Orenbuch, R. Weitzman, J. Frazer, M. Dias, D. Franceschi, Y. Gal, and D. S. Marks. 2024. “ProteinGym: Large-scale benchmarks for protein fitness prediction and design.” Advances in Neural Information Processing Systems 64331–64379. Red Hook, NY: Curran Associates, Inc.
O’Leary, N. A., M. W. Wright, J. R. Brister, S. Ciufo, D. Haddad, R. McVeigh, B. Rajput, B. Robbertse, B. Smith-White, D. Ako-Adjei, A. Astashyn, A. Badretdin, Y. Bao, O. Blinkova, V. Brover, V. Chetvernin, J. Choi, E. Cox, O. Ermolaeva, C. M. Farrell, T. Goldfarb, T. Gupta, D. Haft, E. Hatcher, W. Hlavina, V. S. Joardar, V. K. Kodali, W. Li, D. Maglott, P. Masterson, K. M. McGarvey, M. R. Murphy, K. O’Neill, S. Pujar, S. H. Rangwala, D. Rausch, L. D. Riddick, C. Schoch, A. Shkeda, S. S. Storz, H. Sun, F. Thibaud-Nissen, I. Tolstoy, R. E. Tully, A. R. Vatsan, C. Wallin, D. Webb, W. Wu, M. J. Landrum, A. Kimchi, T. Tatusova, M. DiCuccio, P. Kitts, T. D. Murphy, and K. D. Pruitt. 2016. “Reference sequence (RefSeq) database at NCBI: Current status, taxonomic expansion, and functional annotation.” Nucleic Acids Research 44(D1):D733–D745. https://doi.org/10.1093/nar/gkv1189.
Olsen, T. H., F. Boyles, and C. M. Deane. 2022. “Observed Antibody Space: A diverse database of cleaned, annotated, and translated unpaired and paired antibody sequences.” Protein Science 31(1):141–146. https://doi.org/10.1002/pro.4205.
Olsen, T. H., I. H. Moal, and C. M. Deane. 2022. “AbLang: An antibody language model for completing antibody sequences.” Bioinformatics Advances 2(1). https://doi.org/10.1093/bioadv/vbac046.
Olson, R. D., R. Assaf, T. Brettin, N. Conrad, C. Cucinell, J. J. Davis, D. M. Dempsey, A. Dickerman, E. M. Dietrich, R. W. Kenyon, M. Kuscuoglu, E. J. Lefkowitz, J. Lu, D. Machi, C. Macken, C. Mao, A. Niewiadomska, M. Nguyen, G. J. Olsen, J. C. Overbeek, B. Parrello, V. Parrello, J. S. Porter, G. D. Pusch, M. Shukla, I. Singh, L. Stewart, G. Tan, C. Thomas, M. VanOeffelen, V. Vonstein, Z. S. Wallace, A. S. Warren, A. R. Wattam, F. Xia, H. Yoo, Y. Zhang, C. M. Zmasek, R. H. Scheuermann, and R. L. Stevens. 2023. “Introducing the Bacterial and Viral Bioinformatics Resource Center (BV-BRC): A resource combining PATRIC, IRD and ViPR.” Nucleic Acids Research 51(D1):D678–D689. https://doi.org/10.1093/nar/gkac1003.
Outeiral, C., and C. M. Deane. 2024. “Codon language embeddings provide strong signals for use in protein engineering.” Nature Machine Intelligence 6:170–179. https://doi.org/10.1038/s42256-024-00791-0.
Ouyang, L., J. Wu, X. Jiang, D. Almeida, C. L. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, J. Schulman, J. Hilton, F. Kelton, L. Miller, M. Simens, A. Askell, P. Welinder, P. Christiano, J. Leike, and R. Lowe. 2022. “Training language models to follow instructions with human feedback.” arXiv. https://doi.org/10.48550/arXiv.2203.02155.
Parks, D. H., M. Chuvochina, C. Rinke, A. J. Mussig, P.-A. Chaumeil, and P. Hugenholtz. 2022. “GTDB: An ongoing census of bacterial and archaeal diversity through a phylogenetically consistent, rank normalized and complete genome-based taxonomy.” Nucleic Acids Research 50(D1):D785–D794. https://doi.org/10.1093/nar/gkab776.
Peng, X., S. Luo, J. Guan, Q. Xie, J. Peng, and J. Ma. 2022. “Pocket2Mol: Efficient molecular sampling based on 3D protein pockets.” arXiv. https://doi.org/10.48550/arXiv.2205.07249.
Penić, R. J., T. Vlašić, R. G. Huber, Y. Wan, and M. Šikić. 2024. “RiNALMo: General-purpose RNA language models can generalize well on structure prediction tasks.” arXiv. https://doi.org/10.48550/arXiv.2403.00043.
Pesant, S., F. Not, M. Picheral, S. Kandels-Lewis, N. Le Bescot, G. Gorsky, D. Iudicone, E. Karsenti, S. Speich, R. Troublé, C. Dimier, S. Searson, S. G. Acinas, P. Bork, E. Boss, C. Bowler, C. De Vargas, M. Follows, G. Gorsky, N. Grimsley, P. Hingamp, D. Iudicone, O. Jaillon, S. Kandels-Lewis, L. Karp-Boss, E. Karsenti, U. Krzic, F. Not, H. Ogata, S. Pesant, J. Raes, E. G. Reynaud, C. Sardet, M. Sieracki, S. Speich, L. Stemmann, M. B. Sullivan, S. Sunagawa, D. Velayoudon, J. Weissenbach, and P. Wincker. 2015. “Open science resources for the discovery and analysis of Tara Oceans data.” Scientific Data 2:150023. https://doi.org/10.1038/sdata.2015.23.
Poli, M., S. Massaroli, E. Nguyen, D. Y. Fu, T. Dao, S. Baccus, Y. Bengio, S. Ermon, and C. Ré. 2023. “Hyena hierarchy: Towards larger convolutional language models.” arXiv. https://doi.org/10.48550/arXiv.2302.10866.
Poli, M., A. W. Thomas, E. Nguyen, P. Ponnusamy, B. Deiseroth, K. Kersting, T. Suzuki, B. Hie, S. Ermon, C. Ré, C. Zhang, and S. Massaroli. 2024. “Mechanistic design and scaling of hybrid architectures.” arXiv. https://doi.org/10.48550/arXiv.2403.17844.
Powell, B. M., and J. H. Davis. 2024. “Learning structural heterogeneity from cryo-electron subtomograms with tomoDRGN.” Nature Methods 21:1525–1536. https://doi.org/10.1038/s41592-024-02210-z.
Prihoda, D., J. Maamary, A. Waight, V. Juan, L. Fayadat-Dilman, D. Svozil, and D. A. Bitton. 2022. “BioPhi: A platform for antibody design, humanization, and humanness evaluation based on natural antibody repertoires and deep learning.” mAbs 14(1). https://doi.org/10.1080/19420862.2021.2020203.
Punjani, A., J. L. Rubinstein, D. J. Fleet, and M. A. Brubaker. 2017. “cryoSPARC: Algorithms for rapid unsupervised cryo-EM structure determination.” Nature Methods 14:290–296. https://doi.org/10.1038/nmeth.4169.
Punjani, A., and D. J. Fleet. 2021. “3D variability analysis: Resolving continuous flexibility and discrete heterogeneity from single particle cryo-EM.” Journal of Structural Biology 213(2):107702. https://doi.org/10.1016/j.jsb.2021.107702.
Radford, A., J. Wu, R. Child, D. Luan, D. Amodei, and I. Sutskever. 2019. “Language models are unsupervised multitask learners.” OpenAI. https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf. (accessed November 6, 2024).
Rafailov, R., A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn. 2024. “Direct preference optimization: Your language model is secretly a reward model.” arXiv. https://doi.org/10.48550/arXiv.2305.18290.
Rangan, R., R. Feathers, S. Khavnekar, A. Lerer, J. D. Johnston, R. Kelley, M. Obr, A. Kotecha, and E. D. Zhong. 2024. “CryoDRGN-ET: Deep reconstructing generative networks for visualizing dynamic biomolecules inside cells.” Nature Methods 21:1537–1545. https://doi.org/:10.1038/s41592-024-02340-4.
Rao, R., N. Bhattacharya, N. Thomas, Y. Duan, P. Chen, J. Canny, P. Abbeel, and Y. Song. 2019. “Evaluating protein transfer learning with TAPE.” Advances in Neural Information Processing Systems 32:9689–9701.
Rapp, J. T., B. J. Bremer, and P. A. Romero. 2024. “Self-driving laboratories to autonomously navigate the protein fitness landscape.” Nature Chemical Engineering 1:97–107. https://doi.org/10.1038/s44286-023-00002-4.
Rasmussen, C. E., and C. K. I. Williams. 2005. Gaussian Processes for Machine Learning. Cambridge: MIT Press.
Reddy, A. J., X. Geng, M. H. Herschl, S. Kolli, A. Kumar, P. D. Hsu, S. Levine, and N. M. Ioannidis. 2024. “Designing cell-type-specific promoter sequences using conservative model-based optimization.” bioRxiv. https://doi.org/10.1101/2024.06.23.600232.
Regev, A., S. A. Teichmann, E. S. Lander, I. Amit, C. Benoist, E. Birney, B. Bodenmiller, P. Campbell, P. Carninci, M. Clatworthy, H. Clevers, B. Deplancke, I. Dunham, J. Eberwine, R. Eils, W. Enard, A. Farmer, L. Fugger, B. Göttgens, N. Hacohen, M. Haniffa, M. Hemberg, S. Kim, P. Klenerman, A. Kriegstein, E. Lein, S. Linnarsson, E. Lundberg, J. Lundeberg, P. Majumder, J. C. Marioni, M. Merad, M. Mhlanga, M. Nawijn, M. Netea, G. Nolan, D. Pe’er, A. Phillipakis, C. P. Ponting, S. Quake, W. Reik, O. Rozenblatt-Rosen, J. Sanes, R. Satija, T. N. Schumacher, A. Shalek, E. Shapiro, P. Sharma, J. W. Shin, O. Stegle, M. Stratton, M. J. T. Stubbington, F. J. Theis, M. Uhlen, A. Van Oudenaarden, A. Wagner, F. Watt, J. Weissman, B. Wold, R. Xavier, and N. Yosef. 2017. “The human cell atlas.” eLife 6:e27041. https://doi.org/10.7554/eLife.27041.
Ren, Z., L. Jiang, Y. Di, D. Zhang, J. Gong, J. Gong, Q. Jiang, Z. Fu, P. Sun, B. Zhou, and M. Ni. 2024. “CodonBERT: a BERT-based architecture tailored for codon optimization using the cross-attention mechanism.” Bioinformatics 40(7). https://doi.org/10.1093/bioinformatics/btae330.
Richardson, L., B. Allen, G. Baldi, M. Beracochea, M. L. Bileschi, T. Burdett, J. Burgin, J. Caballero-Pérez, G. Cochrane, L. J. Colwell, T. Curtis, A. Escobar-Zepeda, T. A. Gurbich, V. Kale, A. Korobeynikov, S. Raj, A. B. Rogers, E. Sakharova, S. Sanchez, D. J. Wilkinson, and R. D. Finn. 2023. “MGnify: The microbiome sequence data analysis resource in 2023.” Nucleic Acids Research 51(D1):D753–D759. https://doi.org/10.1093/nar/gkac1080.
Riesselman, A. J., J. B. Ingraham, and D. S. Marks. 2018. “Deep generative models of genetic variation capture the effects of mutations.” Nature Methods 15:816–822. https://doi.org/10.1038/s41592-018-0138-4.
Rives, A., J. Meier, T. Sercu, S. Goyal, Z. Lin, J. Liu, D. Guo, M. Ott, C. L. Zitnick, J. Ma, and R. Fergus. 2021. “Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences.” Proceedings of the National Academy of Sciences 118(15):e2016239118. https://doi.org/10.1073/pnas.2016239118.
Romero, P. A., A. Krause, and F. H. Arnold. 2013. “Navigating the protein fitness landscape with Gaussian processes.” Proceedings of the National Academy of Sciences 110(3):E193–E201. https://doi.org/10.1073/pnas.1215251110.
Ruffolo, J. A., J. J. Gray, and J. Sulam. 2021. “Deciphering antibody affinity maturation with language models and weakly supervised learning.” arXiv. https://doi.org/10.48550/arXiv.2112.07782.
Rumelhart, D. E., G. E. Hinton, and R. J. Williams. 1986. “Learning representations by back-propagating errors.” Nature 323:533–536. https://doi.org/10.1038/323533a0.
Sayers, E. W., M. Cavanaugh, K. Clark, J. Ostell, K. D. Pruitt, and I. Karsch-Mizrachi. 2019. “GenBank.” Nucleic Acids Research 48(D1):D84–D86. https://doi.org/10.1093/nar/gkz956.
Scarselli, F., M. Gori, A. C. Tsoi, M. Hagenbuchner, and G. Monfardini. 2009. “The Graph Neural Network Model.” IEEE Transactions on Neural Networks 20(1):6180. https://doi.org/10.1109/TNN.2008.2005605.
Schiff, Y., C.-H. Kao, A. Gokaslan, T. Dao, A. Gu, and V. Kuleshov. 2024. “Caduceus: Bi-directional equivariant long-range DNA sequence modeling.” arXiv. https://doi.org/10.48550/arXiv.2403.03234.
Schulman, J., F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. 2017. “Proximal policy optimization algorithms.” arXiv. https://doi.org/10.48550/arXiv.1707.06347.
Senior, A. W., R. Evans, J. Jumper, J. Kirkpatrick, L. Sifre, T. Green, C. Qin, A. Žídek, A. W. R. Nelson, A. Bridgland, H. Penedones, S. Petersen, K. Simonyan, S. Crossan, P. Kohli, D. T. Jones, D. Silver, K. Kavukcuoglu, and D. Hassabis. 2020. “Improved protein structure prediction using potentials from deep learning.” Nature 577:706–710. https://doi.org/10.1038/s41586-019-1923-7.
Shu, Y., and J. McCauley. 2017. “GISAID: Global Initiative on Sharing All Influenza Data–from vision to reality.” Euro Surveillance 22(13):30494. https://doi.org/10.2807/1560-7917.ES.2017.22.13.30494.
Starr, T. N., A. J. Greaney, W. W. Hannon, A. N. Loes, K. Hauser, J. R. Dillen, E. Ferri, A. G. Farrell, B. Dadonaite, M. McCallum, K. A. Matreyek, D. Corti, D. Veesler, G. Snell, and J. D. Bloom. 2022. “Shifting mutational constraints in the SARS-CoV-2 receptor-binding domain during viral evolution.” Science 377(6604):420–424. https://doi.org/10.1126/science.abo7896.
Starr, T. N., A. J. Greaney, S. K. Hilton, D. Ellis, K. H. D. Crawford, A. S. Dingens, M. J. Navarro, J. E. Bowen, M. A. Tortorici, A. C. Walls, N. P. King, D. Veesler, and J. D. Bloom. 2020. “Deep mutational scanning of SARS-CoV-2 receptor binding domain reveals constraints on folding and ACE2 binding.” Cell 182(5):1295–1310.e20. https://doi.org/10.1016/j.cell.2020.08.012.
Suzek, B. E., H. Huang, P. McGarvey, R. Mazumder, and C. H. Wu. 2007. “UniRef: Comprehensive and non-redundant UniProt reference clusters.” Bioinformatics 23(10):1282–1288. https://doi.org/10.1093/bioinformatics/btm098.
Sweeney, B. A., A. I. Petrov, B. Burkov, R. D. Finn, A. Bateman, M. Szymanski, W. M. Karlowski, J. Gorodkin, S. E. Seemann, J. J. Cannone, R. R. Gutell, P. Fey, S. Basu, S. Kay, G. Cochrane, K. Billis, D. Emmert, S. J. Marygold, R. P. Huntley, R. C. Lovering, A. Frankish, P. P. Chan, T. M. Lowe, E. Bruford, R. Seal, J. Vandesompele, P.-J. Volders, M. Paraskevopoulou, L. Ma, Z. Zhang, S. Griffiths-Jones, J. M. Bujnicki, P. Boccaletto, J. A. Blake, C. J. Bult, R. Chen, Y. Zhao, V. Wood, K. Rutherford, E. Rivas, J. Cole, S. J. F. Laulederkind, M. Shimoyama, M. E. Gillespie, M. Orlic-Milacic, I. Kalvari, E. Nawrocki, S. R. Engel, J. M. Cherry, S. Team, T. Z. Berardini, A. Hatzigeorgiou, D. Karagkouni, K. Howe, P. Davis, M. Dinger, S. He, M. Yoshihama, N. Kenmochi, P. F. Stadler, and K. P. Williams. 2019. “RNAcentral: A hub of information for non-coding RNA sequences.” Nucleic Acids Research 47(D1):D221–D229. https://doi.org/10.1093/nar/gky1034.
Szklarczyk, D., A. Santos, C. Von Mering, L. J. Jensen, P. Bork, and M. Kuhn. 2016. “STITCH 5: Augmenting protein-chemical interaction networks with tissue and affinity data.” Nucleic Acids Research 44(D1):D380–D384. https://doi.org/10.1093/nar/gkv1277.
Thadani, N. N., S. Gurev, P. Notin, N. Youssef, N. J. Rollins, D. Ritter, C. Sander, Y. Gal, and D. S. Marks. 2023. “Learning from prepandemic data to forecast viral escape.” Nature 622:818–825. https://doi.org/10.1038/s41586-023-06617-0.
Single-cell transcriptomics of 20 mouse organs creates a Tabula Muris. Nature 562:367–372. https://doi.org/10.1038/s41586-018-0590-4.
Theodoris, C. V., L. Xiao, A. Chopra, M. D. Chaffin, Z. R. Al Sayed, M. C. Hill, H. Mantineo, E. M. Brydon, Z. Zeng, X. S. Liu, and P. T. Ellinor. 2023. “Transfer learning enables predictions in network biology.” Nature 618:616–624. https://doi.org/10.1038/s41586-023-06139-9.
The Tabula Muris Consortium. 2018. “Single-cell transcriptomics of 20 mouse organs creates a Tabula Muris.” Nature 562:367–372. doi: 10.1038/s41586-018-0590-4.
UniProt Consortium. 2019. “UniProt: A worldwide hub of protein knowledge.” Nucleic Acids Research 47:D506–D515. https://doi.org/10.1093/nar/gky1049.
Varadi, M., S. Anyango, M. Deshpande, S. Nair, C. Natassia, G. Yordanova, D. Yuan, O. Stroe, G. Wood, A. Laydon, A. Žídek, T. Green, K. Tunyasuvunakool, S. Petersen, J. Jumper, E. Clancy, R. Green, A. Vora, M. Lutfi, M. Figurnov, A. Cowie, N. Hobbs, P. Kohli, G. Kleywegt, E. Birney, D. Hassabis, and S. Velankar. 2022. “AlphaFold Protein Structure Database: Massively expanding the structural coverage of protein-sequence space with high-accuracy models.” Nucleic Acids Research 50(D1):D439–D444. https://doi.org/10.1093/nar/gkab1061.
Vaswani, A., N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin. 2017. “Attention is all you need.” arXiv. https://doi.org/10.48550/arXiv.1706.03762.
Wagle, S., R. D. Smith, A. J. Dominic, D. DasGupta, S. K. Tripathi, and H. A. Carlson. 2023. “Sunsetting Binding MOAD with its last data update and the addition of 3D-ligand polypharmacology tools.” Scientific Reports 13:3008. https://doi.org/10.1038/s41598-023-29996-w.
Wang, J., S. Lisanza, D. Juergens, D. Tischer, J. L. Watson, K. M. Castro, R. Ragotte, A. Saragovi, L. F. Milles, M. Baek, I. Anishchenko, W. Yang, D. R. Hicks, M. Expòsit, T. Schlichthaerle, J.-H. Chun, J. Dauparas, N. Bennett, B. I. M. Wicky, A. Muenks, F. DiMaio, B. Correia, S. Ovchinnikov, and D. Baker. 2022. “Scaffolding protein functional sites using deep learning.” Science 377(6604):387–394. https://doi.org/10.1126/science.abn2100.
Wang, N., J. Bian, Y. Li, X. Li, S. Mumtaz, L. Kong, and H. Xiong. 2024. “Multi-purpose RNA language modelling with motif-aware pretraining and type-guided fine-tuning.” Nature Machine Intelligence 6:548–557. https://doi.org/10.1038/s42256-024-00836-4.
Wang, R., X. Fang, Y. Lu, C.-Y. Yang, and S. Wang. 2005. “The PDBbind database: Methodologies and updates.” Journal of Medicinal Chemistry 48(12):4111–4119. https://doi.org/10.1021/jm048957q.
Wang, X., R. Gu, Z. Chen, Y. Li, X. Ji, G. Ke, and H. Wen. 2023. “Uni-RNA: Universal pre-trained models revolutionize RNA research.” bioRxiv. https://doi.org/10.1101/2023.07.11.548588.
Watson, J. L., D. Juergens, N. R. Bennett, B. L. Trippe, J. Yim, H. E. Eisenach, W. Ahern, A. J. Borst, R. J. Ragotte, L. F. Milles, B. I. M. Wicky, N. Hanikel, S. J. Pellock, A. Courbet, W. Sheffler, J. Wang, P. Venkatesh, I. Sappington, S. V. Torres, A. Lauko, V. De Bortoli, E. Mathieu, S. Ovchinnikov, R. Barzilay, T. S. Jaakkola, F. DiMaio, M. Baek, and D. Baker. 2023. “De novo design of protein structure and function with RFdiffusion.” Nature 620:1089–1100. https://doi.org/10.1038/s41586-023-06415-8.
Wu, N. C., J. Otwinowski, A. J. Thompson, C. M. Nycholat, A. Nourmohammad, and I. A. Wilson. 2020. “Major antigenic site B of human influenza H3N2 viruses has an evolving local fitness landscape.” Nature Communications 11:1233. https://doi.org/10.1038/s41467-020-15102-5.
Wu, R., F. Ding, R. Wang, R. Shen, X. Zhang, S. Luo, C. Su, Z. Wu, Q. Xie, B. Berger, J. Ma, and J. Peng. 2022. “High-resolution de novo structure prediction from primary sequence.” bioRxiv. https://doi.org/10.1101/2022.07.21.500999.
Wu, Z., S. Pan, F. Chen, G. Long, C. Zhang, and P. S. Yu. 2019. “A comprehensive survey on graph neural networks.” IEEE Transactions on Neural Networks and Learning Systems 32(1):4–24. https://doi.org/10.1109/TNNLS.2020.2978386.
Yandell, M., and D. Ence. 2012. “A beginner’s guide to eukaryotic genome annotation.” Nature Reviews Genetics 13:329–342. https://doi.org/10.1038/nrg3174.
Yang, F., W. Wang, F. Wang, Y. Fang, D. Tang, J. Huang, H. Lu, and J. Yao. 2022. “scBERT as a large-scale pretrained deep language model for cell type annotation of singlecell RNA-seq data.” Nature Machine Intelligence 4:852–866. https://doi.org/10.1038/s42256-022-00534-z.
Yang, K. K., N. Fusi, and A. X. Lu. 2024. “Convolutions are competitive with transformers for protein sequence pretraining.” Cell Systems 15(3):286–294.e2. https://doi.org/10.1016/j.cels.2024.01.008.
Yates, A. D., J. Allen, R. M. Amode, A. G. Azov, M. Barba, A. Becerra, J. Bhai, L. I. Campbell, M. Carbajo Martinez, M. Chakiachvili, K. Chougule, M. Christensen, B. Contreras-Moreira, A. Cuzick, L. Da Rin Fioretto, P. Davis, N. H. De Silva, S. Diamantakis, S. Dyer, J. Elser, C. V. Filippi, A. Gall, D. Grigoriadis, C. Guijarro-Clarke, P. Gupta, K. E. Hammond-Kosack, K. L. Howe, P. Jaiswal, V. Kaikala, V. Kumar, S. Kumari, N. Langridge, T. Le, M. Luypaert, G. L. Maslen, T. Maurel, B. Moore, M. Muffato, A. Mushtaq, G. Naamati, S. Naithani, A. Olson, A. Parker, M. Paulini, H. Pedro, E. Perry, J. Preece, M. Quinton-Tulloch, F. Rodgers, M. Rosello, M. Ruffier, J. Seager, V. Sitnik, M. Szpak, J. Tate, M. K. Tello-Ruiz, S. J. Trevanion, M. Urban, D. Ware, S. Wei, G. Williams, A. Winterbottom, M. Zarowiecki, R. D. Finn, and P. Flicek. 2022. “Ensembl Genomes 2022: An expanding genome resource for non-vertebrates.” Nucleic Acids Research 50(D1):D996–D1003. https://doi.org/10.1093/nar/gkab1007.
Youngblut, N. D., J. de la Cuesta-Zuluaga, G. H. Reischer, S. Dauser, N. Schuster, C. Walzer, G. Stalder, A. H. Farnleitner, and R. E. Ley. 2020. “Large-scale metagenome assembly reveals novel animal-associated microbial genomes, biosynthetic gene clusters, and other genetic diversity.” mSystems 5(6):e01045-20. https://doi.org/10.1128/mSystems.01045-20.
Zhang, P., H. Wang, H. Xu, L. Wei, L. Liu, Z. Hu, and X. Wang. 2023. “Deep flanking sequence engineering for efficient promoter design using DeepSEED.” Nature Communications 14:6309. https://doi.org/10.1038/s41467-023-41899-y.
Zhang, Y., B. D. Aevermann, T. K. Anderson, D. F. Burke, G. Dauphin, Z. Gu, S. He, S. Kumar, C. N. Larsen, A. J. Lee, X. Li, C. MacKen, C. Mahaffey, B. E. Pickett, B. Reardon, T. Smith, L. Stewart, C. Suloway, G. Sun, L. Tong, A. L. Vincent, B. Walters, S. Zaremba, H. Zhao, L. Zhou, C. Zmasek, E. B. Klem, and R. H. Scheuermann. 2017. “Influenza Research Database: An integrated bioinformatics resource for influenza virus research.” Nucleic Acids Research 45(D1):D466–D474. https://doi.org/10.1093/nar/gkw857.
Zhong, E. D., T. Bepler, B. Berger, and J. H. Davis. 2021. “CryoDRGN: Reconstruction of heterogeneous cryo-EM structures using neural networks.” Nature Methods 18:176–185. https://doi.org/10.1038/s41592-020-01049-4.
Zvyagin, M., A. Brace, K. Hippe, Y. Deng, B. Zhang, C. O. Bohorquez, A. Clyde, B. Kale, D. Perez-Rivera, H. Ma, C. M. Mann, M. Irvin, D. G. Ozgulbas, N. Vassilieva, J. G. Pauloski, L. Ward, V. Hayot-Sasson, M. Emani, S. Foreman, Z. Xie, D. Lin, M. Shukla, W. Nie, J. Romero, C. Dallago, A. Vahdat, C. Xiao, T. Gibbs, I. Foster, J. J. Davis, M. E. Papka, T. Brettin, R. Stevens, A. Anandkumar, V. Vishwanath, and A. Ramanathan. 2023. “GenSLMs: Genome-scale language models reveal SARS-CoV-2 evolutionary dynamics.” The International Journal of High Performance Computing Applications 37(6):683–705. https://doi.org/10.1177/10943420231201154.
























































